This document has been reviewed by W3C Members and other interested parties
and has been endorsed by the Director as a W3C Recommendation. It is a stable
document and may be used as reference material or cited as a normative reference
from another document. W3C's role in making the Recommendation is to draw
attention to the specification and to promote its widespread deployment. This
enhances the functionality and interoperability of the Web.
This version of this document incorporates some editorial changes from
earlier versions.
A list of current W3C Recommendations and other technical documents can be
found at http://www.w3.org/TR/.
1 Introduction
 1.1 Purpose
1.1 Purpose
The [XML
1.0 (Second Edition)] specification defines limited facilities for applying
datatypes to document content in that documents may contain or refer to DTDs
that assign types to elements and attributes. However, document authors,
including authors of traditional documents and those transporting
data in XML, often require a higher degree of type checking to ensure
robustness in document understanding and data interchange.
The table below offers two typical examples of XML instances in which
datatypes are implicit: the instance on the left represents a billing invoice,
the instance on the right a memo or perhaps an email message in XML.
| Data oriented |
Document oriented |
<invoice>
<orderDate>1999-01-21</orderDate>
<shipDate>1999-01-25</shipDate>
<billingAddress>
<name>Ashok Malhotra</name>
<street>123 Microsoft Ave.</street>
<city>Hawthorne</city>
<state>NY</state>
<zip>10532-0000</zip>
</billingAddress>
<voice>555-1234</voice>
<fax>555-4321</fax>
</invoice> |
<memo importance='high'
date='1999-03-23'>
<from>Paul V. Biron</from>
<to>Ashok Malhotra</to>
<subject>Latest draft</subject>
<body>
We need to discuss the latest
draft <emph>immediately</emph>.
Either email me at <email>
mailto:paul.v.biron@kp.org</email>
or call <phone>555-9876</phone>
</body>
</memo> |
The invoice contains several dates and telephone numbers, the postal
abbreviation for a state (which comes from an enumerated list of sanctioned
values), and a ZIP code (which takes a definable regular form). The memo
contains many of the same types of information: a date, telephone number, email
address and an "importance" value (from an enumerated list, such as "low",
"medium" or "high"). Applications which process invoices and memos need to raise
exceptions if something that was supposed to be a date or telephone number does
not conform to the rules for valid dates or telephone numbers.
In both cases, validity constraints exist on the content of the instances
that are not expressible in XML DTDs. The limited datatyping facilities in XML
have prevented validating XML processors from supplying the rigorous type
checking required in these situations. The result has been that individual
applications writers have had to implement type checking in an ad hoc manner.
This specification addresses the need of both document authors and applications
writers for a robust, extensible datatype system for XML which could be
incorporated into XML processors. As discussed below, these datatypes could be
used in other XML-related standards as well.
 1.2 Requirements
1.2 Requirements
The [XML
Schema Requirements] document spells out concrete requirements to be
fulfilled by this specification, which state that the XML Schema Language must:
- provide for primitive data typing, including byte, date, integer,
sequence, SQL and Java primitive datatypes, etc.;
- define a type system that is adequate for import/export from database
systems (e.g., relational, object, OLAP);
- distinguish requirements relating to lexical data representation vs. those
governing an underlying information set;
- allow creation of user-defined datatypes, such as datatypes that are
derived from existing datatypes and which may constrain certain of its
properties (e.g., range, precision, length, format).
1.3 Scope
This portion of the XML Schema Language discusses datatypes that can be used
in an XML Schema. These datatypes can be specified for element content that
would be specified as #PCDATA and
attribute values of various
types in a DTD. It is the intention of this specification that it be usable
outside of the context of XML Schemas for a wide range of other XML-related
activities such as [XSL] and [RDF
Schema].
1.4 Terminology
The terminology used to describe XML Schema Datatypes is defined in the body
of this specification. The terms defined in the following list are used in
building those definitions and in describing the actions of a datatype
processor:
- [Definition:] for compatibility
- A feature of this specification included solely to ensure that schemas
which use this feature remain compatible with [XML 1.0
(Second Edition)]
- [Definition:] may
- Conforming documents and processors are permitted to but need not behave
as described.
- [Definition:] match
- (Of strings or names:) Two strings or names being compared must be
identical. Characters with multiple possible representations in ISO/IEC 10646
(e.g. characters with both precomposed and base+diacritic forms) match only if
they have the same representation in both strings. No case folding is
performed. (Of strings and rules in the grammar:) A string matches a
grammatical production if it belongs to the language generated by that
production.
- [Definition:] must
- Conforming documents and processors are required to behave as described;
otherwise they are in ·error·.
- [Definition:] error
- A violation of the rules of this specification; results are undefined.
Conforming software ·may· detect and report an
error and ·may· recover from it.
2 Type System
This section describes the conceptual framework behind the type system
defined in this specification. The framework has been influenced by the [ISO
11404] standard on language-independent datatypes as well as the datatypes
for [SQL]
and for programming languages such as Java.
The datatypes discussed in this specification are computer representations of
well known abstract concepts such as integer and date. It is not
the place of this specification to define these abstract concepts; many other
publications provide excellent definitions.
2.1 Datatype
[Definition:] In this
specification, a datatype is a 3-tuple, consisting of a) a set of
distinct values, called its ·value space·, b) a set of
lexical representations, called its ·lexical space·, and c) a set of
·facet·s that characterize
properties of the ·value space·, individual values
or lexical items.
2.2 Value space
[Definition:] A
value space is the set of values for a given datatype. Each value in the
value space of a datatype is denoted by one or more literals in its ·lexical space·.
The ·value space· of a given
datatype can be defined in one of the following ways:
- defined axiomatically from fundamental notions (intensional definition)
[see ·primitive·]
- enumerated outright (extensional definition) [see ·enumeration·]
- defined by restricting the ·value space· of an already
defined datatype to a particular subset with a given set of properties [see ·derived·]
- defined as a combination of values from one or more already defined ·value space·(s) by a specific
construction procedure [see ·list· and ·union·]
·value space·s have certain
properties. For example, they always have the property of ·cardinality·, some definition
of equality and might be ·ordered·, by which individual
values within the ·value space· can be compared to
one another. The properties of ·value space·s that are
recognized by this specification are defined in Fundamental
facets (§2.4.1).
2.3 Lexical space
In addition to its ·value space·, each datatype
also has a lexical space.
[Definition:] A
lexical space is the set of valid literals for a datatype.
For example, "100" and "1.0E2" are two different literals from the ·lexical space· of float which
both denote the same value. The type system defined in this specification
provides a mechanism for schema designers to control the set of values and the
corresponding set of acceptable literals of those values for a datatype.
NOTE: The literals in the ·lexical space·s defined in
this specification have the following characteristics:
- Interoperability:
- The number of literals for each value has been kept small; for many
datatypes there is a one-to-one mapping between literals and values. This
makes it easy to exchange the values between different systems. In many
cases, conversion from locale-dependent representations will be required on
both the originator and the recipient side, both for computer processing and
for interaction with humans.
- Basic readability:
- Textual, rather than binary, literals are used. This makes hand editing,
debugging, and similar activities possible.
- Ease of parsing and serializing:
- Where possible, literals correspond to those found in common programming
languages and libraries.
2.3.1 Canonical Lexical
Representation
While the datatypes defined in this specification have, for the most part, a
single lexical representation i.e. each value in the datatype's ·value space· is denoted by a
single literal in its ·lexical space·, this is not
always the case. The example in the previous section showed two literals for the
datatype float which
denote the same value. Similarly, there ·may· be several literals for
one of the date or time datatypes that denote the same value using different
timezone indicators.
[Definition:] A canonical
lexical representation is a set of literals from among the valid set of
literals for a datatype such that there is a one-to-one mapping between literals
in the canonical lexical representation and values in the ·value space·.
2.4 Facets
[Definition:] A
facet is a single defining aspect of a ·value space·. Generally
speaking, each facet characterizes a ·value space· along independent
axes or dimensions.
The facets of a datatype serve to distinguish those aspects of one datatype
which differ from other datatypes. Rather than being defined solely in
terms of a prose description the datatypes in this specification are defined in
terms of the synthesis of facet values which together determine the ·value space· and properties of
the datatype.
Facets are of two types: fundamental facets that define the datatype
and non-fundamental or constraining facets that constrain the
permitted values of a datatype.
2.5 Datatype dichotomies
It is useful to categorize the datatypes defined in this specification along
various dimensions, forming a set of characterization dichotomies.
2.5.1 Atomic vs. list vs. union datatypes
The first distinction to be made is that between ·atomic·, ·list· and ·union· datatypes.
For example, a single token which ·match·es Nmtoken from
[XML 1.0
(Second Edition)] could be the value of an ·atomic· datatype (NMTOKEN);
while a sequence of such tokens could be the value of a ·list· datatype (NMTOKENS).
2.5.1.1 Atomic datatypes
·atomic· datatypes can be either
·primitive· or ·derived·. The ·value space· of an ·atomic· datatype is a set of
"atomic" values, which for the purposes of this specification, are not further
decomposable. The ·lexical space· of an ·atomic· datatype is a set of
literals whose internal structure is specific to the datatype in
question.
2.5.1.2 List datatypes
Several type systems (such as the one described in [ISO
11404]) treat ·list· datatypes as special
cases of the more general notions of aggregate or collection datatypes.
·list· datatypes are always ·derived·. The ·value space· of a ·list· datatype is a set of
finite-length sequences of ·atomic· values. The ·lexical space· of a ·list· datatype is a set of
literals whose internal structure is a white space separated sequence of
literals of the ·atomic· datatype of the items
in the ·list· (where whitespace ·match·es S in [XML 1.0 (Second
Edition)]).
[Definition:] The ·atomic· datatype that
participates in the definition of a ·list· datatype is known as the
itemType of that ·list· datatype.
<simpleType name='sizes'>
<list itemType='decimal'/>
</simpleType>
<cerealSizes xsi:type='sizes'> 8 10.5 12 </cerealSizes>
A ·list· datatype can be ·derived· from an ·atomic· datatype whose ·lexical space· allows
whitespace (such as string or
anyURI).
In such a case, regardless of the input, list items will be separated at
whitespace boundaries.
<simpleType name='listOfString'>
<list itemType='string'/>
</simpleType>
<someElement xsi:type='listOfString'>
this is not list item 1
this is not list item 2
this is not list item 3
</someElement>
When a datatype is ·derived· from a ·list· datatype, the following
·constraining facet·s apply:
For each of ·length·, ·maxLength· and ·minLength·, the unit of
length is measured in number of list items. The value of ·whiteSpace· is fixed to the
value collapse.
The canonical-lexical-representation
for the ·list· datatype is defined as
the lexical form in which each item in the ·list· has the canonical lexical
representation of its ·itemType·.
2.5.1.3 Union datatypes
The ·value space· and ·lexical space· of a ·union· datatype are the union
of the ·value space·s and ·lexical space·s of its ·memberTypes·. ·union· datatypes are always ·derived·. Currently, there are
no ·built-in· ·union· datatypes.
A prototypical example of a
·union· type is the
maxOccurs
attribute on the
element
element in XML Schema itself: it is a union of nonNegativeInteger and an
enumeration with the single member, the string "unbounded", as shown below.
<attributeGroup name="occurs">
<attribute name="minOccurs" type="nonNegativeInteger"
default="1"/>
<attribute name="maxOccurs">
<simpleType>
<union>
<simpleType>
<restriction base='nonNegativeInteger'/>
</simpleType>
<simpleType>
<restriction base='string'>
<enumeration value='unbounded'/>
</restriction>
</simpleType>
</union>
</simpleType>
</attribute>
</attributeGroup>
Any number (greater than 1) of ·atomic· or ·list· ·datatype·s can participate in a
·union· type.
[Definition:] The
datatypes that participate in the definition of a ·union· datatype are known as
the memberTypes of that ·union· datatype.
The order in which the ·memberTypes· are specified in
the definition (that is, the order of the <simpleType> children of the
<union> element, or the order of the QNames in
the memberTypes attribute) is significant. During validation, an element
or attribute's value is validated against the ·memberTypes· in the order in
which they appear in the definition until a match is found. The evaluation order
can be overridden with the use of xsi:type.
For example, given the definition below, the first
instance of the <size> element validates correctly as an
integer
(§3.3.13), the second and third as
string
(§3.2.1).
<xsd:element name='size'>
<xsd:simpleType>
<xsd:union>
<xsd:simpleType>
<xsd:restriction base='integer'/>
</xsd:simpleType>
<xsd:simpleType>
<xsd:restriction base='string'/>
</xsd:simpleType>
</xsd:union>
</xsd:simpleType>
</xsd:element>
<size>1</size>
<size>large</size>
<size xsi:type='xsd:string'>1</size>
The canonical-lexical-representation
for a ·union· datatype is defined as
the lexical form in which the values have the canonical lexical representation
of the appropriate ·memberTypes·.
NOTE: A datatype which is ·atomic· in this specification
need not be an "atomic" datatype in any programming language used to implement
this specification. Likewise, a datatype which is a ·list· in this specification
need not be a "list" datatype in any programming language used to implement
this specification. Furthermore, a datatype which is a ·union· in this specification
need not be a "union" datatype in any programming language used to implement
this specification.
2.5.2 Primitive vs. derived datatypes
Next, we distinguish between ·primitive· and ·derived· datatypes.
- [Definition:] Primitive datatypes are
those that are not defined in terms of other datatypes; they exist ab
initio.
- [Definition:] Derived datatypes are
those that are defined in terms of other datatypes.
For example, in this specification, float is a
well-defined mathematical concept that cannot be defined in terms of other
datatypes, while a integer
is a special case of the more general datatype decimal.
[Definition:]
There exists a conceptual datatype, whose name is anySimpleType, that is
the simple version of the ur-type
definition from [XML
Schema Part 1: Structures]. anySimpleType can be considered as the ·base type· of all ·primitive· types. The ·value space· of
anySimpleType can be considered to be the ·union· of the ·value space·s of all ·primitive· datatypes.
The datatypes defined by this specification fall into both the ·primitive· and ·derived· categories. It is felt
that a judiciously chosen set of ·primitive· datatypes will serve
the widest possible audience by providing a set of convenient datatypes that can
be used as is, as well as providing a rich enough base from which the variety of
datatypes needed by schema designers can be ·derived·.
In the example above, integer
is ·derived· from decimal.
NOTE: A datatype which is ·primitive· in this
specification need not be a "primitive" datatype in any programming language
used to implement this specification. Likewise, a datatype which is ·derived· in this
specification need not be a "derived" datatype in any programming language
used to implement this specification.
As described in more detail in XML
Representation of Simple Type Definition Schema Components (§4.1.2), each ·user-derived· datatype ·must· be defined in terms of
another datatype in one of three ways: 1) by assigning ·constraining facet·s which
serve to restrict the ·value space· of the ·user-derived· datatype to a
subset of that of the ·base type·; 2) by creating a ·list· datatype whose ·value space· consists of
finite-length sequences of values of its ·itemType·; or 3) by creating a
·union· datatype whose ·value space· consists of the
union of the ·value space· its ·memberTypes·.
2.5.3 Built-in vs. user-derived
datatypes
Conceptually there is no difference between the ·built-in· ·derived· datatypes included in
this specification and the ·user-derived· datatypes which
will be created by individual schema designers. The ·built-in· ·derived· datatypes are those
which are believed to be so common that if they were not defined in this
specification many schema designers would end up "reinventing" them.
Furthermore, including these ·derived· datatypes in this
specification serves to demonstrate the mechanics and utility of the datatype
generation facilities of this specification.
NOTE: A datatype which is ·built-in· in this
specification need not be a "built-in" datatype in any programming language
used to implement this specification. Likewise, a datatype which is ·user-derived· in this
specification need not be a "user-derived" datatype in any programming
language used to implement this specification.
3 Built-in datatypes
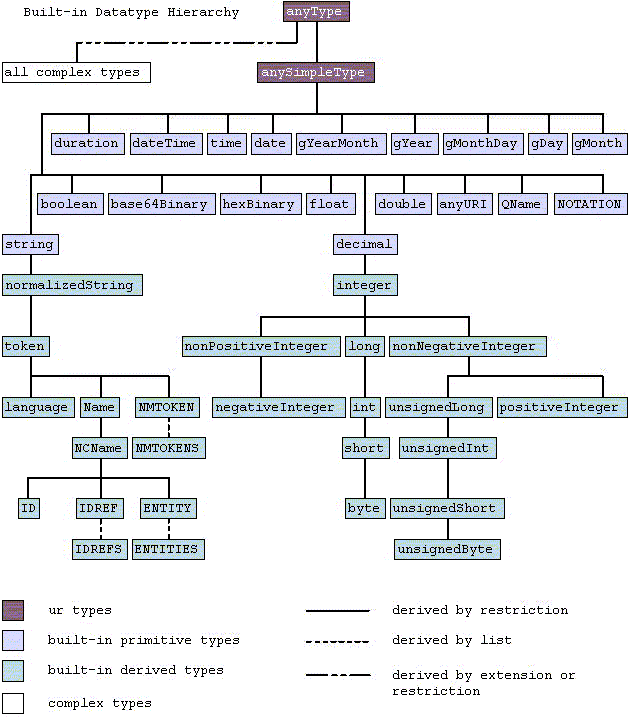
Each built-in datatype in this specification (both ·primitive· and ·derived·) can be uniquely
addressed via a URI Reference constructed as follows:
- the base URI is the URI of the XML Schema namespace
- the fragment identifier is the name of the datatype
For example, to address the int datatype,
the URI is:
http://www.w3.org/2001/XMLSchema#int
Additionally, each facet definition element can be uniquely addressed via a
URI constructed as follows:
- the base URI is the URI of the XML Schema namespace
- the fragment identifier is the name of the facet
For example, to address the maxInclusive facet, the URI is:
http://www.w3.org/2001/XMLSchema#maxInclusive
Additionally, each facet usage in a built-in datatype definition can be
uniquely addressed via a URI constructed as follows:
- the base URI is the URI of the XML Schema namespace
- the fragment identifier is the name of the datatype, followed by a period
(".") followed by the name of the facet
For example, to address the usage of the maxInclusive facet in the definition
of int, the URI is:
http://www.w3.org/2001/XMLSchema#int.maxInclusive
3.1 Namespace considerations
The ·built-in· datatypes defined by
this specification are designed to be used with the XML Schema definition
language as well as other XML specifications. To facilitate usage within the XML
Schema definition language, the ·built-in· datatypes in this
specification have the namespace name:
- http://www.w3.org/2001/XMLSchema
To facilitate usage in specifications other than the XML Schema definition
language, such as those that do not want to know anything about aspects of the
XML Schema definition language other than the datatypes, each ·built-in· datatype is also
defined in the namespace whose URI is:
- http://www.w3.org/2001/XMLSchema-datatypes
This applies to both ·built-in· ·primitive· and ·built-in· ·derived· datatypes.
Each ·user-derived· datatype is also
associated with a unique namespace. However, ·user-derived· datatypes do not
come from the namespace defined by this specification; rather, they come from
the namespace of the schema in which they are defined (see XML
Representation of Schemas in [XML
Schema Part 1: Structures]).
3.2 Primitive datatypes
The ·primitive· datatypes defined by
this specification are described below. For each datatype, the ·value space· and ·lexical space· are defined, ·constraining facet·s which
apply to the datatype are listed and any datatypes ·derived· from this datatype are
specified.
·primitive· datatypes can only
be added by revisions to this specification.
3.2.2 boolean
[Definition:] boolean has the ·value space· required to
support the mathematical concept of binary-valued logic: {true, false}.
3.2.2.1 Lexical
representation
An instance of a datatype that is defined as ·boolean· can have the following
legal literals {true, false, 1, 0}.
3.2.2.2 Canonical
representation
The canonical representation for boolean is the set of literals {true,
false}.
3.2.3 decimal
[Definition:] decimal represents arbitrary
precision decimal numbers. The ·value space· of decimal
is the set of the values i × 10^-n, where i and n are
integers such that n >= 0. The ·order-relation· on
decimal is: x < y iff y - x is positive.
[Definition:] The ·value space· of types derived
from decimal with a value for ·totalDigits· of p is the
set of values i × 10^-n, where n and i are integers such
that p >= n >= 0 and the number of significant decimal digits in
i is less than or equal to p.
[Definition:] The ·value space· of types derived
from decimal with a value for ·fractionDigits· of s is
the set of values i × 10^-n, where i and n are integers
such that 0 <= n <= s.
NOTE: All ·minimally conforming·
processors ·must· support decimal numbers
with a minimum of 18 decimal digits (i.e., with a ·totalDigits· of 18). However,
·minimally conforming·
processors ·may· set an
application-defined limit on the maximum number of decimal digits they are
prepared to support, in which case that application-defined maximum number ·must· be clearly documented.
3.2.3.1 Lexical
representation
decimal has a lexical representation consisting of a finite-length
sequence of decimal digits (#x30-#x39) separated by a period as a decimal
indicator. If ·totalDigits· is specified, the
number of digits must be less than or equal to ·totalDigits·. If ·fractionDigits· is specified,
the number of digits following the decimal point must be less than or equal to
the ·fractionDigits·. An optional
leading sign is allowed. If the sign is omitted, "+" is assumed. Leading and
trailing zeroes are optional. If the fractional part is zero, the period and
following zero(es) can be omitted. For example: -1.23, 12678967.543233,
+100000.00, 210.
3.2.3.2 Canonical
representation
The canonical representation for decimal is defined by prohibiting
certain options from the Lexical
representation (§3.2.3.1). Specifically, the preceding optional "+" sign is
prohibited. The decimal point is required. Leading and trailing zeroes are
prohibited subject to the following: there must be at least one digit to the
right and to the left of the decimal point which may be a zero.
3.2.4 float
[Definition:] float corresponds to the IEEE
single-precision 32-bit floating point type [IEEE
754-1985]. The basic ·value space· of float
consists of the values m × 2^e, where m is an integer whose
absolute value is less than 2^24, and e is an integer between -149
and 104, inclusive. In addition to the basic ·value space· described above,
the ·value space· of float
also contains the following special values: positive and negative zero,
positive and negative infinity and not-a-number. The ·order-relation· on float
is: x < y iff y - x is positive. Positive zero is greater than
negative zero. Not-a-number equals itself and is greater than all float values
including positive infinity.
A literal in the ·lexical space· representing a
decimal number d maps to the normalized value in the ·value space· of float
that is closest to d in the sense defined by [Clinger,
WD (1990)]; if d is exactly halfway between two such values then the
even value is chosen.
3.2.4.1 Lexical representation
float values have a lexical representation consisting of a mantissa
followed, optionally, by the character "E" or "e", followed by an exponent. The
exponent ·must· be an integer.
The mantissa must be a decimal
number. The representations for exponent and mantissa must follow the lexical
rules for integer
and decimal.
If the "E" or "e" and the following exponent are omitted, an exponent value of 0
is assumed.
The special values positive and negative zero, positive and negative
infinity and not-a-number have lexical representations 0,
-0, INF, -INF and NaN,
respectively.
For example, -1E4, 1267.43233E12, 12.78e-2, 12 and INF are all
legal literals for float.
3.2.4.2 Canonical
representation
The canonical representation for float is defined by prohibiting
certain options from the Lexical
representation (§3.2.4.1). Specifically, the exponent must be indicated by
"E". Leading zeroes and the preceding optional "+" sign are prohibited in the
exponent. For the mantissa, the preceding optional "+" sign is prohibited and
the decimal point is required. For the exponent, the preceding optional "+" sign
is prohibited. Leading and trailing zeroes are prohibited subject to the
following: number representations must be normalized such that there is a single
digit to the left of the decimal point and at least a single digit to the right
of the decimal point.
3.2.5 double
[Definition:] The
double datatype corresponds to IEEE double-precision 64-bit floating
point type [IEEE
754-1985]. The basic ·value space· of double
consists of the values m × 2^e, where m is an integer whose
absolute value is less than 2^53, and e is an integer between
-1075 and 970, inclusive. In addition to the basic ·value space· described above,
the ·value space· of double
also contains the following special values: positive and negative zero,
positive and negative infinity and not-a-number. The ·order-relation· on
double is: x < y iff y - x is positive. Positive zero is
greater than negative zero. Not-a-number equals itself and is greater than all
double values including positive infinity.
A literal in the ·lexical space· representing a
decimal number d maps to the normalized value in the ·value space· of double
that is closest to d; if d is exactly halfway between two such
values then the even value is chosen. This is the best approximation of
d ([Clinger,
WD (1990)], [Gay, DM
(1990)]), which is more accurate than the mapping required by [IEEE
754-1985].
3.2.5.1 Lexical
representation
double values have a lexical representation consisting of a mantissa
followed, optionally, by the character "E" or "e", followed by an exponent. The
exponent ·must· be an integer. The
mantissa must be a decimal number. The representations for exponent and mantissa
must follow the lexical rules for integer
and decimal.
If the "E" or "e" and the following exponent are omitted, an exponent value of 0
is assumed.
The special values positive and negative zero, positive and negative
infinity and not-a-number have lexical representations 0,
-0, INF, -INF and NaN,
respectively.
For example, -1E4, 1267.43233E12, 12.78e-2, 12 and INF are all
legal literals for double.
3.2.5.2 Canonical
representation
The canonical representation for double is defined by prohibiting
certain options from the Lexical
representation (§3.2.5.1). Specifically, the exponent must be indicated by
"E". Leading zeroes and the preceding optional "+" sign are prohibited in the
exponent. For the mantissa, the preceding optional "+" sign is prohibited and
the decimal point is required. For the exponent, the preceding optional "+" sign
is prohibited. Leading and trailing zeroes are prohibited subject to the
following: number representations must be normalized such that there is a single
digit to the left of the decimal point and at least a single digit to the right
of the decimal point.
3.2.6 duration
[Definition:]
duration represents a duration of time. The ·value space· of duration
is a six-dimensional space where the coordinates designate the Gregorian year,
month, day, hour, minute, and second components defined in § 5.5.3.2 of [ISO
8601], respectively. These components are ordered in their significance by
their order of appearance i.e. as year, month, day, hour, minute, and second.
3.2.6.1 Lexical representation
The lexical representation for duration is the [ISO
8601] extended format PnYn MnDTnH
nMnS, where nY represents the number of years, nM
the number of months, nD the number of days, 'T' is the date/time
separator, nH the number of hours, nM the number of minutes and
nS the number of seconds. The number of seconds can include decimal
digits to arbitrary precision.
The values of the Year, Month, Day, Hour and Minutes components are not
restricted but allow an arbitrary integer. Similarly, the value of the Seconds
component allows an arbitrary decimal. Thus, the lexical representation of
duration does not follow the alternative format of § 5.5.3.2.1 of [ISO
8601].
An optional preceding minus sign ('-') is allowed, to indicate a negative
duration. If the sign is omitted a positive duration is indicated. See also ISO 8601
Date and Time Formats (§D).
For example, to indicate a duration of 1 year, 2 months, 3 days, 10 hours,
and 30 minutes, one would write: P1Y2M3DT10H30M. One could also
indicate a duration of minus 120 days as: -P120D.
Reduced precision and truncated representations of this format are allowed
provided they conform to the following:
- If the number of years, months, days, hours, minutes, or seconds in any
expression equals zero, the number and its corresponding designator ·may· be omitted. However, at
least one number and its designator ·must· be present.
- The seconds part ·may· have a decimal fraction.
- The designator 'T' shall be absent if all of the time items are absent.
The designator 'P' must always be present.
For example, P1347Y, P1347M and P1Y2MT2H are all allowed; P0Y1347M and
P0Y1347M0D are allowed. P-1347M is not allowed although -P1347M is allowed.
P1Y2MT is not allowed.
3.2.6.2 Order relation on duration
In general, the ·order-relation· on
duration is a partial order since there is no determinate relationship
between certain durations such as one month (P1M) and 30 days (P30D). The ·order-relation· of two
duration values x and y is x < y iff s+x < s+y
for each qualified dateTime
s in the list below. These values for s cause the greatest
deviations in the addition of dateTimes and durations. Addition of durations to
time instants is defined in Adding
durations to dateTimes (§E).
- 1696-09-01T00:00:00Z
- 1697-02-01T00:00:00Z
- 1903-03-01T00:00:00Z
- 1903-07-01T00:00:00Z
The following table shows the strongest relationship that can be determined
between example durations. The symbol <> means that the order relation is
indeterminate. Note that because of leap-seconds, a seconds field can vary from
59 to 60. However, because of the way that addition is defined in Adding
durations to dateTimes (§E), they are still totally ordered.
| |
Relation |
| P1Y |
> P364D |
<> P365D |
|
<> P366D |
< P367D |
| P1M |
> P27D |
<> P28D |
<> P29D |
<> P30D |
<> P31D |
< P32D |
| P5M |
> P149D |
<> P150D |
<> P151D |
<> P152D |
<> P153D |
< P154D |
Implementations are free to optimize the computation of the ordering
relationship. For example, the following table can be used to compare durations
of a small number of months against days.
| |
Months |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
... |
| Days |
Minimum |
28 |
59 |
89 |
120 |
150 |
181 |
212 |
242 |
273 |
303 |
334 |
365 |
393 |
... |
| Maximum |
31 |
62 |
92 |
123 |
153 |
184 |
215 |
245 |
276 |
306 |
337 |
366 |
397 |
... |
3.2.6.4 Totally ordered durations
Certain derived datatypes of durations can be guaranteed have a total order.
For this, they must have fields from only one row in the list below and the time
zone must either be required or prohibited.
- year, month
- day, hour, minute, second
For example, a datatype could be defined to correspond to the [SQL]
datatype Year-Month interval that required a four digit year field and a two
digit month field but required all other fields to be unspecified. This datatype
could be defined as below and would have a total order.
<simpleType name='SQL-Year-Month-Interval'>
<restriction base='duration'>
<pattern value='P\p{Nd}{4}Y\p{Nd}{2}M'/>
</restriction>
</simpleType>
3.2.7 dateTime
[Definition:]
dateTime represents a specific instant of time. The ·value space· of dateTime
is the space of Combinations of date and time of day values as defined in
§ 5.4 of [ISO
8601].
3.2.7.1 Lexical representation
A single lexical representation, which is a subset of the lexical
representations allowed by [ISO
8601], is allowed for dateTime. This lexical representation is the [ISO
8601] extended format CCYY-MM-DDThh:mm:ss where "CC" represents the century,
"YY" the year, "MM" the month and "DD" the day, preceded by an optional leading
"-" sign to indicate a negative number. If the sign is omitted, "+" is assumed.
The letter "T" is the date/time separator and "hh", "mm", "ss" represent hour,
minute and second respectively. Additional digits can be used to increase the
precision of fractional seconds if desired i.e the format ss.ss... with any
number of digits after the decimal point is supported. The fractional seconds
part is optional; other parts of the lexical form are not optional. To
accommodate year values greater than 9999 additional digits can be added to the
left of this representation. Leading zeros are required if the year value would
otherwise have fewer than four digits; otherwise they are forbidden. The year
0000 is prohibited.
The CCYY field must have at least four digits, the MM, DD, SS, hh, mm and ss
fields exactly two digits each (not counting fractional seconds); leading zeroes
must be used if the field would otherwise have too few digits.
This representation may be immediately followed by a "Z" to indicate
Coordinated Universal Time (UTC) or, to indicate the time zone, i.e. the
difference between the local time and Coordinated Universal Time, immediately
followed by a sign, + or -, followed by the difference from UTC represented as
hh:mm (note: the minutes part is required). See ISO 8601
Date and Time Formats (§D) for details about legal values in the various
fields. If the time zone is included, both hours and minutes must be present.
For example, to indicate 1:20 pm on May the 31st, 1999 for Eastern Standard
Time which is 5 hours behind Coordinated Universal Time (UTC), one would write:
1999-05-31T13:20:00-05:00.
3.2.7.2 Canonical representation
The canonical representation for dateTime is defined by prohibiting
certain options from the Lexical
representation (§3.2.7.1). Specifically, either the time zone must be
omitted or, if present, the time zone must be Coordinated Universal Time (UTC)
indicated by a "Z".
3.2.7.3 Order relation on dateTime
In general, the ·order-relation· on
dateTime is a partial order since there is no determinate relationship
between certain instants. For example, there is no determinate ordering between
(a) 2000-01-20T12:00:00 and (b) 2000-01-20T12:00:00Z. Based on timezones
currently in use, (c) could vary from 2000-01-20T12:00:00+12:00 to
2000-01-20T12:00:00-13:00. It is, however, possible for this range to expand or
contract in the future, based on local laws. Because of this, the following
definition uses a somewhat broader range of indeterminate values:
+14:00..-14:00.
The following definition uses the notation S[year] to represent the year
field of S, S[month] to represent the month field, and so on. The notation (Q
& "-14:00") means adding the timezone -14:00 to Q, where Q did not already
have a timezone. This is a logical explanation of the process. Actual
implementations are free to optimize as long as they produce the same
results.
The ordering between two dateTimes P and Q is defined by the following
algorithm:
A.Normalize P and Q. That is, if there is a timezone present, but it is not
Z, convert it to Z using the addition operation defined in Adding
durations to dateTimes (§E)
- Thus 2000-03-04T23:00:00+03:00 normalizes to 2000-03-04T20:00:00Z
B. If P and Q either both have a time zone or both do not have a time zone,
compare P and Q field by field from the year field down to the second field, and
return a result as soon as it can be determined. That is:
- For each i in {year, month, day, hour, minute, second}
- If P[i] and Q[i] are both not specified, continue to the next i
- If P[i] is not specified and Q[i] is, or vice versa, stop and return P
<> Q
- If P[i] < Q[i], stop and return P < Q
- If P[i] > Q[i], stop and return P > Q
- Stop and return P = Q
C.Otherwise, if P contains a time zone and Q does not, compare as follows:
- P < Q if P < (Q with time zone +14:00)
- P > Q if P > (Q with time zone -14:00)
- P <> Q otherwise, that is, if (Q with time zone +14:00) < P <
(Q with time zone -14:00)
D. Otherwise, if P does not contain a time zone and Q does, compare as
follows:
- P < Q if (P with time zone -14:00) < Q.
- P > Q if (P with time zone +14:00) > Q.
- P <> Q otherwise, that is, if (P with time zone +14:00) < Q <
(P with time zone -14:00)
Examples:
| Determinate |
Indeterminate |
| 2000-01-15T00:00:00 < 2000-02-15T00:00:00 |
2000-01-01T12:00:00 <>
1999-12-31T23:00:00Z |
| 2000-01-15T12:00:00 < 2000-01-16T12:00:00Z |
2000-01-16T12:00:00 <>
2000-01-16T12:00:00Z |
| |
2000-01-16T00:00:00 <>
2000-01-16T12:00:00Z |
3.2.7.4 Totally ordered dateTimes
Certain derived types from dateTime can be guaranteed have a total
order. To do so, they must require that a specific set of fields are always
specified, and that remaining fields (if any) are always unspecified. For
example, the date datatype without time zone is defined to contain exactly year,
month, and day. Thus dates without time zone have a total order among
themselves.
3.2.8 time
[Definition:] time
represents an instant of time that recurs every day. The ·value space· of time is
the space of time of day values as defined in § 5.3 of [ISO
8601]. Specifically, it is a set of zero-duration daily time
instances.
Since the lexical representation allows an optional time zone indicator,
time values are partially ordered because it may not be able to determine
the order of two values one of which has a time zone and the other does not. The
order relation on time values is the Order
relation on dateTime (§3.2.7.3) using an arbitrary date. See also Adding
durations to dateTimes (§E). Pairs of time values with or without
time zone indicators are totally ordered.
3.2.8.1 Lexical representation
The lexical representation for time is the left truncated lexical
representation for dateTime:
hh:mm:ss.sss with optional following time zone indicator. For example, to
indicate 1:20 pm for Eastern Standard Time which is 5 hours behind Coordinated
Universal Time (UTC), one would write: 13:20:00-05:00. See also ISO 8601
Date and Time Formats (§D).
3.2.8.2 Canonical representation
The canonical representation for time is defined by prohibiting
certain options from the Lexical
representation (§3.2.8.1). Specifically, either the time zone must be
omitted or, if present, the time zone must be Coordinated Universal Time (UTC)
indicated by a "Z". Additionally, the canonical representation for midnight is
00:00:00.
3.2.9 date
[Definition:] date
represents a calendar date. The ·value space· of date is
the set of Gregorian calendar dates as defined in § 5.2.1 of [ISO
8601]. Specifically, it is a set of one-day long, non-periodic instances
e.g. lexical 1999-10-26 to represent the calendar date 1999-10-26, independent
of how many hours this day has.
Since the lexical representation allows an optional time zone indicator,
date values are partially ordered because it may not be possible to
unequivocally determine the order of two values one of which has a time zone and
the other does not. If date values are considered as periods of time, the
order relation on date values is the order relation on their starting
instants. This is discussed in Order
relation on dateTime (§3.2.7.3). See also Adding
durations to dateTimes (§E). Pairs of date values with or without
time zone indicators are totally ordered.
3.2.9.1 Lexical representation
The lexical representation for date is the reduced (right truncated)
lexical representation for dateTime:
CCYY-MM-DD. No left truncation is allowed. An optional following time zone
qualifier is allowed as for dateTime.
To accommodate year values outside the range from 0001 to 9999, additional
digits can be added to the left of this representation and a preceding "-" sign
is allowed.
For example, to indicate May the 31st, 1999, one would write: 1999-05-31. See
also ISO 8601
Date and Time Formats (§D).
3.2.10 gYearMonth
[Definition:]
gYearMonth represents a specific gregorian month in a specific gregorian
year. The ·value space· of
gYearMonth is the set of Gregorian calendar months as defined in § 5.2.1
of [ISO
8601]. Specifically, it is a set of one-month long, non-periodic instances
e.g. 1999-10 to represent the whole month of 1999-10, independent of how many
days this month has.
Since the lexical representation allows an optional time zone indicator,
gYearMonth values are partially ordered because it may not be possible to
unequivocally determine the order of two values one of which has a time zone and
the other does not. If gYearMonth values are considered as periods of
time, the order relation on gYearMonth values is the order relation on
their starting instants. This is discussed in Order
relation on dateTime (§3.2.7.3). See also Adding
durations to dateTimes (§E). Pairs of gYearMonth values with or
without time zone indicators are totally ordered.
NOTE: Because month/year combinations in one calendar only
rarely correspond to month/year combinations in other calendars, values of
this type are not, in general, convertible to simple values corresponding to
month/year combinations in other calendars. This type should therefore be used
with caution in contexts where conversion to other calendars is desired.
3.2.10.1 Lexical representation
The lexical representation for gYearMonth is the reduced (right
truncated) lexical representation for dateTime:
CCYY-MM. No left truncation is allowed. An optional following time zone
qualifier is allowed. To accommodate year values outside the range from 0001 to
9999, additional digits can be added to the left of this representation and a
preceding "-" sign is allowed.
For example, to indicate the month of May 1999, one would write: 1999-05. See
also ISO 8601
Date and Time Formats (§D).
3.2.11 gYear
[Definition:]
gYear represents a gregorian calendar year. The ·value space· of gYear is
the set of Gregorian calendar years as defined in § 5.2.1 of [ISO
8601]. Specifically, it is a set of one-year long, non-periodic instances
e.g. lexical 1999 to represent the whole year 1999, independent of how many
months and days this year has.
Since the lexical representation allows an optional time zone indicator,
gYear values are partially ordered because it may not be possible to
unequivocally determine the order of two values one of which has a time zone and
the other does not. If gYear values are considered as periods of time,
the order relation on gYear values is the order relation on their
starting instants. This is discussed in Order
relation on dateTime (§3.2.7.3). See also Adding
durations to dateTimes (§E). Pairs of gYear values with or without
time zone indicators are totally ordered.
NOTE: Because years in one calendar only rarely correspond
to years in other calendars, values of this type are not, in general,
convertible to simple values corresponding to years in other calendars. This
type should therefore be used with caution in contexts where conversion to
other calendars is desired.
3.2.11.1 Lexical representation
The lexical representation for gYear is the reduced (right truncated)
lexical representation for dateTime:
CCYY. No left truncation is allowed. An optional following time zone qualifier
is allowed as for dateTime.
To accommodate year values outside the range from 0001 to 9999, additional
digits can be added to the left of this representation and a preceding "-" sign
is allowed.
For example, to indicate 1999, one would write: 1999. See also ISO 8601
Date and Time Formats (§D).
3.2.12 gMonthDay
[Definition:]
gMonthDay is a gregorian date that recurs, specifically a day of the year
such as the third of May. Arbitrary recurring dates are not supported by this
datatype. The ·value space· of
gMonthDay is the set of calendar dates, as defined in § 3 of [ISO
8601]. Specifically, it is a set of one-day long, annually periodic
instances.
Since the lexical representation allows an optional time zone indicator,
gMonthDay values are partially ordered because it may not be possible to
unequivocally determine the order of two values one of which has a time zone and
the other does not. If gMonthDay values are considered as periods of
time, the order relation on gMonthDay values is the order relation on
their starting instants. This is discussed in Order
relation on dateTime (§3.2.7.3). See also Adding
durations to dateTimes (§E). Pairs of gMonthDay values with or
without time zone indicators are totally ordered.
NOTE: Because day/month combinations in one calendar only
rarely correspond to day/month combinations in other calendars, values of this
type do not, in general, have any straightforward or intuitive representation
in terms of most other calendars. This type should therefore be used with
caution in contexts where conversion to other calendars is desired.
3.2.12.1 Lexical representation
The lexical representation for gMonthDay is the left truncated lexical
representation for date:
--MM-DD. An optional following time zone qualifier is allowed as for date. No
preceding sign is allowed. No other formats are allowed. See also ISO 8601
Date and Time Formats (§D).
This datatype can be used to represent a specific day in a month. To say, for
example, that my birthday occurs on the 14th of September ever year.
3.2.13 gDay
[Definition:] gDay
is a gregorian day that recurs, specifically a day of the month such as the 5th
of the month. Arbitrary recurring days are not supported by this datatype. The
·value space· of gDay is
the space of a set of calendar dates as defined in § 3 of [ISO
8601]. Specifically, it is a set of one-day long, monthly periodic
instances.
This datatype can be used to represent a specific day of the month. To say,
for example, that I get my paycheck on the 15th of each month.
Since the lexical representation allows an optional time zone indicator,
gDay values are partially ordered because it may not be possible to
unequivocally determine the order of two values one of which has a time zone and
the other does not. If gDay values are considered as periods of time, the
order relation on gDay values is the order relation on their starting
instants. This is discussed in Order
relation on dateTime (§3.2.7.3). See also Adding
durations to dateTimes (§E). Pairs of gDay values with or without
time zone indicators are totally ordered.
NOTE: Because days in one calendar only rarely correspond
to days in other calendars, values of this type do not, in general, have any
straightforward or intuitive representation in terms of most other calendars.
This type should therefore be used with caution in contexts where conversion
to other calendars is desired.
3.2.13.1 Lexical representation
The lexical representation for gDay is the left truncated lexical
representation for date: ---DD
. An optional following time zone qualifier is allowed as for date. No
preceding sign is allowed. No other formats are allowed. See also ISO 8601
Date and Time Formats (§D).
3.2.14 gMonth
[Definition:]
gMonth is a gregorian month that recurs every year. The ·value space· of gMonth
is the space of a set of calendar months as defined in § 3 of [ISO
8601]. Specifically, it is a set of one-month long, yearly periodic
instances.
This datatype can be used to represent a specific month. To say, for example,
that Thanksgiving falls in the month of November.
Since the lexical representation allows an optional time zone indicator,
gMonth values are partially ordered because it may not be possible to
unequivocally determine the order of two values one of which has a time zone and
the other does not. If gMonth values are considered as periods of time,
the order relation on gMonth is the order relation on their starting
instants. This is discussed in Order
relation on dateTime (§3.2.7.3). See also Adding
durations to dateTimes (§E). Pairs of gMonth values with or without
time zone indicators are totally ordered.
NOTE: Because months in one calendar only rarely correspond
to months in other calendars, values of this type do not, in general, have any
straightforward or intuitive representation in terms of most other calendars.
This type should therefore be used with caution in contexts where conversion
to other calendars is desired.
3.2.14.1 Lexical representation
The lexical representation for gMonth is the left and right truncated
lexical representation for date:
--MM--. An optional following time zone qualifier is allowed as for date. No
preceding sign is allowed. No other formats are allowed. See also ISO 8601
Date and Time Formats (§D).
3.2.15 hexBinary
[Definition:]
hexBinary represents arbitrary hex-encoded binary data. The ·value space· of
hexBinary is the set of finite-length sequences of binary octets.
3.2.15.1 Lexical
Representation
hexBinary has a lexical representation where each binary octet is
encoded as a character tuple, consisting of two hexadecimal digits ([0-9a-fA-F])
representing the octet code. For example, "0FB7" is a hex encoding for
the 16-bit integer 4023 (whose binary representation is 111110110111).
3.2.15.2 Canonical Rrepresentation
The canonical representation for hexBinary is defined by prohibiting
certain options from the Lexical
Representation (§3.2.15.1). Specifically, the lower case hexadecimal digits
([a-f]) are not allowed.
3.2.16 base64Binary
[Definition:]
base64Binary represents Base64-encoded arbitrary binary data. The ·value space· of
base64Binary is the set of finite-length sequences of binary octets. For
base64Binary data the entire binary stream is encoded using the Base64
Content-Transfer-Encoding defined in Section 6.8 of [RFC
2045].
3.2.17 anyURI
[Definition:]
anyURI represents a Uniform Resource Identifier Reference (URI). An
anyURI value can be absolute or relative, and may have an optional
fragment identifier (i.e., it may be a URI Reference). This type should be used
to specify the intention that the value fulfills the role of a URI as defined by
[RFC
2396], as amended by [RFC
2732].
The mapping from anyURI values to URIs is as defined in Section 5.4 Locator
Attribute of [XML Linking
Language] (see also Section 8 Character
Encoding in URI References of [Character
Model]). This means that a wide range of internationalized resource
identifiers can be specified when an anyURI is called for, and still be
understood as URIs per [RFC
2396], as amended by [RFC
2732], where appropriate to identify resources.
NOTE: Each URI scheme imposes specialized syntax rules for
URIs in that scheme, including restrictions on the syntax of allowed fragement
identifiers. Because it is impractical for processors to check that a value is
a context-appropriate URI reference, this specification follows the lead of [RFC
2396] (as amended by [RFC
2732]) in this matter: such rules and restrictions are not part of type
validity and are not checked by ·minimally conforming·
processors. Thus in practice the above definition imposes only very modest
obligations on ·minimally conforming·
processors.
3.2.17.1 Lexical
representation
The ·lexical space· of anyURI
is finite-length character sequences which, when the algorithm defined in
Section 5.4 of [XML Linking
Language] is applied to them, result in strings which are legal URIs
according to [RFC
2396], as amended by [RFC
2732].
NOTE: Spaces are, in principle, allowed in the ·lexical space· of
anyURI, however, their use is highly discouraged (unless they are
encoded by %20).
3.3 Derived datatypes
This section gives conceptual definitions for all ·built-in· ·derived· datatypes defined by
this specification. The XML representation used to define ·derived· datatypes (whether ·built-in· or ·user-derived·) is given in
section XML
Representation of Simple Type Definition Schema Components (§4.1.2) and the
complete definitions of the ·built-in· ·derived· datatypes are provided
in Appendix A Schema for
Datatype Definitions (normative) (§A).
3.3.1 normalizedString
[Definition:]
normalizedString represents white space normalized strings. The ·value space· of
normalizedString is the set of strings that do not contain the carriage
return (#xD), line feed (#xA) nor tab (#x9) characters. The ·lexical space· of
normalizedString is the set of strings that do not contain the carriage
return (#xD) nor tab (#x9) characters. The ·base type· of
normalizedString is string.
3.3.1.2 Derived datatypes
The following ·built-in· datatypes are ·derived· from
normalizedString:
3.3.2 token
[Definition:]
token represents tokenized strings. The ·value space· of token is
the set of strings that do not contain the line feed (#xA) nor tab (#x9)
characters, that have no leading or trailing spaces (#x20) and that have no
internal sequences of two or more spaces. The ·lexical space· of token
is the set of strings that do not contain the line feed (#xA) nor tab (#x9)
characters, that have no leading or trailing spaces (#x20) and that have no
internal sequences of two or more spaces. The ·base type· of token is
normalizedString.
3.3.13 integer
[Definition:]
integer is ·derived· from decimal
by fixing the value of ·fractionDigits· to be 0. This
results in the standard mathematical concept of the integer numbers. The ·value space· of integer
is the infinite set {...,-2,-1,0,1,2,...}. The ·base type· of integer is
decimal.
3.3.13.1 Lexical
representation
integer has a lexical representation consisting of a finite-length
sequence of decimal digits (#x30-#x39) with an optional leading sign. If the
sign is omitted, "+" is assumed. For example: -1, 0, 12678967543233, +100000.
3.3.13.2 Canonical representation
The canonical representation for integer is defined by prohibiting
certain options from the Lexical
representation (§3.3.13.1). Specifically, the preceding optional "+" sign is
prohibited and leading zeroes are prohibited.
3.3.14 nonPositiveInteger
[Definition:]
nonPositiveInteger is ·derived· from integer
by setting the value of ·maxInclusive· to be 0. This
results in the standard mathematical concept of the non-positive integers. The
·value space· of
nonPositiveInteger is the infinite set {...,-2,-1,0}. The ·base type· of
nonPositiveInteger is integer.
3.3.14.1 Lexical
representation
nonPositiveInteger has a lexical representation consisting of a
negative sign ("-") followed by a finite-length sequence of decimal digits
(#x30-#x39). If the sequence of digits consists of all zeros then the sign is
optional. For example: -1, 0, -12678967543233, -100000.
3.3.14.2 Canonical
representation
The canonical representation for nonPositiveInteger is defined by
prohibiting certain options from the Lexical
representation (§3.3.14.1). Specifically, the negative sign ("-") is
required with the token "0" and leading zeroes are prohibited.
3.3.14.4 Derived datatypes
The following ·built-in· datatypes are ·derived· from
nonPositiveInteger:
3.3.15 negativeInteger
[Definition:]
negativeInteger is ·derived· from nonPositiveInteger
by setting the value of ·maxInclusive· to be -1. This
results in the standard mathematical concept of the negative integers. The ·value space· of
negativeInteger is the infinite set {...,-2,-1}. The ·base type· of
negativeInteger is nonPositiveInteger.
3.3.15.1 Lexical
representation
negativeInteger has a lexical representation consisting of a negative
sign ("-") followed by a finite-length sequence of decimal digits (#x30-#x39).
For example: -1, -12678967543233, -100000.
3.3.15.2 Canonical
representation
The canonical representation for negativeInteger is defined by
prohibiting certain options from the Lexical
representation (§3.3.15.1). Specifically, leading zeroes are prohibited.
3.3.16 long
[Definition:] long
is ·derived· from integer
by setting the value of ·maxInclusive· to be
9223372036854775807 and ·minInclusive· to be
-9223372036854775808. The ·base type· of long is integer.
3.3.16.1 Lexical representation
long has a lexical representation consisting of an optional sign
followed by a finite-length sequence of decimal digits (#x30-#x39). If the sign
is omitted, "+" is assumed. For example: -1, 0, 12678967543233, +100000.
3.3.16.2 Canonical representation
The canonical representation for long is defined by prohibiting
certain options from the Lexical
representation (§3.3.16.1). Specifically, the the optional "+" sign is
prohibited and leading zeroes are prohibited.
3.3.17 int
[Definition:] int
is ·derived· from long by
setting the value of ·maxInclusive· to be 2147483647
and ·minInclusive· to be
-2147483648. The ·base type· of int is long.
3.3.17.1 Lexical representation
int has a lexical representation consisting of an optional sign
followed by a finite-length sequence of decimal digits (#x30-#x39). If the sign
is omitted, "+" is assumed. For example: -1, 0, 126789675, +100000.
3.3.17.2 Canonical representation
The canonical representation for int is defined by prohibiting certain
options from the Lexical
representation (§3.3.17.1). Specifically, the the optional "+" sign is
prohibited and leading zeroes are prohibited.
3.3.18 short
[Definition:]
short is ·derived· from int by
setting the value of ·maxInclusive· to be 32767 and
·minInclusive· to be -32768. The
·base type· of short is
int.
3.3.18.1 Lexical
representation
short has a lexical representation consisting of an optional sign
followed by a finite-length sequence of decimal digits (#x30-#x39). If the sign
is omitted, "+" is assumed. For example: -1, 0, 12678, +10000.
3.3.18.2 Canonical representation
The canonical representation for short is defined by prohibiting
certain options from the Lexical
representation (§3.3.18.1). Specifically, the the optional "+" sign is
prohibited and leading zeroes are prohibited.
3.3.19 byte
[Definition:] byte
is ·derived· from short by
setting the value of ·maxInclusive· to be 127 and ·minInclusive· to be -128. The
·base type· of byte is short.
3.3.19.1 Lexical representation
byte has a lexical representation consisting of an optional sign
followed by a finite-length sequence of decimal digits (#x30-#x39). If the sign
is omitted, "+" is assumed. For example: -1, 0, 126, +100.
3.3.19.2 Canonical representation
The canonical representation for byte is defined by prohibiting
certain options from the Lexical
representation (§3.3.19.1). Specifically, the the optional "+" sign is
prohibited and leading zeroes are prohibited.
3.3.20 nonNegativeInteger
[Definition:]
nonNegativeInteger is ·derived· from integer
by setting the value of ·minInclusive· to be 0. This
results in the standard mathematical concept of the non-negative integers. The
·value space· of
nonNegativeInteger is the infinite set {0,1,2,...}. The ·base type· of
nonNegativeInteger is integer.
3.3.20.1 Lexical
representation
nonNegativeInteger has a lexical representation consisting of an
optional sign followed by a finite-length sequence of decimal digits
(#x30-#x39). If the sign is omitted, "+" is assumed. For example: 1, 0,
12678967543233, +100000.
3.3.20.2 Canonical
representation
The canonical representation for nonNegativeInteger is defined by
prohibiting certain options from the Lexical
representation (§3.3.20.1). Specifically, the the optional "+" sign is
prohibited and leading zeroes are prohibited.
3.3.20.4 Derived datatypes
The following ·built-in· datatypes are ·derived· from
nonNegativeInteger:
3.3.21 unsignedLong
[Definition:]
unsignedLong is ·derived· from nonNegativeInteger
by setting the value of ·maxInclusive· to be
18446744073709551615. The ·base type· of
unsignedLong is nonNegativeInteger.
3.3.21.1 Lexical
representation
unsignedLong has a lexical representation consisting of a
finite-length sequence of decimal digits (#x30-#x39). For example: 0,
12678967543233, 100000.
3.3.21.2 Canonical
representation
The canonical representation for unsignedLong is defined by
prohibiting certain options from the Lexical
representation (§3.3.21.1). Specifically, leading zeroes are prohibited.
3.3.22 unsignedInt
[Definition:]
unsignedInt is ·derived· from unsignedLong
by setting the value of ·maxInclusive· to be 4294967295.
The ·base type· of
unsignedInt is unsignedLong.
3.3.22.1 Lexical
representation
unsignedInt has a lexical representation consisting of a finite-length
sequence of decimal digits (#x30-#x39). For example: 0, 1267896754, 100000.
3.3.22.2 Canonical
representation
The canonical representation for unsignedInt is defined by prohibiting
certain options from the Lexical
representation (§3.3.22.1). Specifically, leading zeroes are prohibited.
3.3.23 unsignedShort
[Definition:]
unsignedShort is ·derived· from unsignedInt
by setting the value of ·maxInclusive· to be 65535. The
·base type· of
unsignedShort is unsignedInt.
3.3.23.1 Lexical
representation
unsignedShort has a lexical representation consisting of a
finite-length sequence of decimal digits (#x30-#x39). For example: 0, 12678,
10000.
3.3.23.2 Canonical
representation
The canonical representation for unsignedShort is defined by
prohibiting certain options from the Lexical
representation (§3.3.23.1). Specifically, the leading zeroes are prohibited.
3.3.23.4 Derived datatypes
The following ·built-in· datatypes are ·derived· from
unsignedShort:
3.3.24 unsignedByte
[Definition:]
unsignedByte is ·derived· from unsignedShort
by setting the value of ·maxInclusive· to be 255. The ·base type· of
unsignedByte is unsignedShort.
3.3.24.1 Lexical
representation
unsignedByte has a lexical representation consisting of a
finite-length sequence of decimal digits (#x30-#x39). For example: 0, 126, 100.
3.3.24.2 Canonical
representation
The canonical representation for unsignedByte is defined by
prohibiting certain options from the Lexical
representation (§3.3.24.1). Specifically, leading zeroes are prohibited.
3.3.25 positiveInteger
[Definition:]
positiveInteger is ·derived· from nonNegativeInteger
by setting the value of ·minInclusive· to be 1. This
results in the standard mathematical concept of the positive integer numbers.
The ·value space· of
positiveInteger is the infinite set {1,2,...}. The ·base type· of
positiveInteger is nonNegativeInteger.
3.3.25.1 Lexical
representation
positiveInteger has a lexical representation consisting of an optional
positive sign ("+") followed by a finite-length sequence of decimal digits
(#x30-#x39). For example: 1, 12678967543233, +100000.
3.3.25.2 Canonical
representation
The canonical representation for positiveInteger is defined by
prohibiting certain options from the Lexical
representation (§3.3.25.1). Specifically, the optional "+" sign is
prohibited and leading zeroes are prohibited.
A Schema for Datatype Definitions (normative)
<?xml version='1.0'?>
<!-- XML Schema schema for XML Schemas: Part 2: Datatypes -->
<!DOCTYPE xs:schema PUBLIC "-//W3C//DTD XMLSCHEMA 200102//EN"
"XMLSchema.dtd" [
<!--
keep this schema XML1.0 DTD valid
-->
<!ENTITY % schemaAttrs 'xmlns:hfp CDATA #IMPLIED'>
<!ELEMENT hfp:hasFacet EMPTY>
<!ATTLIST hfp:hasFacet
name NMTOKEN #REQUIRED>
<!ELEMENT hfp:hasProperty EMPTY>
<!ATTLIST hfp:hasProperty
name NMTOKEN #REQUIRED
value CDATA #REQUIRED>
<!--
Make sure that processors that do not read the external
subset will know about the various IDs we declare
-->
<!ATTLIST xs:simpleType id ID #IMPLIED>
<!ATTLIST xs:maxExclusive id ID #IMPLIED>
<!ATTLIST xs:minExclusive id ID #IMPLIED>
<!ATTLIST xs:maxInclusive id ID #IMPLIED>
<!ATTLIST xs:minInclusive id ID #IMPLIED>
<!ATTLIST xs:totalDigits id ID #IMPLIED>
<!ATTLIST xs:fractionDigits id ID #IMPLIED>
<!ATTLIST xs:length id ID #IMPLIED>
<!ATTLIST xs:minLength id ID #IMPLIED>
<!ATTLIST xs:maxLength id ID #IMPLIED>
<!ATTLIST xs:enumeration id ID #IMPLIED>
<!ATTLIST xs:pattern id ID #IMPLIED>
<!ATTLIST xs:appinfo id ID #IMPLIED>
<!ATTLIST xs:documentation id ID #IMPLIED>
<!ATTLIST xs:list id ID #IMPLIED>
<!ATTLIST xs:union id ID #IMPLIED>
]>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.w3.org/2001/XMLSchema"
version="Id: datatypes.xsd,v 1.52 2001/04/27 11:49:21 ht Exp "
xmlns:hfp="http://www.w3.org/2001/XMLSchema-hasFacetAndProperty"
elementFormDefault="qualified"
blockDefault="#all"
xml:lang="en">
<xs:annotation>
<xs:documentation source="http://www.w3.org/TR/2001/REC-xmlschema-2-20010502/datatypes">
The schema corresponding to this document is normative,
with respect to the syntactic constraints it expresses in the
XML Schema language. The documentation (within <documentation>
elements) below, is not normative, but rather highlights important
aspects of the W3C Recommendation of which this is a part
</xs:documentation>
</xs:annotation>
<xs:annotation>
<xs:documentation>
First the built-in primitive datatypes. These definitions are for
information only, the real built-in definitions are magic. Note in
particular that there is no type named 'anySimpleType'. The
primitives should really be derived from no type at all, and
anySimpleType should be derived as a union of all the primitives.
</xs:documentation>
<xs:documentation>
For each built-in datatype in this schema (both primitive and
derived) can be uniquely addressed via a URI constructed
as follows:
1) the base URI is the URI of the XML Schema namespace
2) the fragment identifier is the name of the datatype
For example, to address the int datatype, the URI is:
http://www.w3.org/2001/XMLSchema#int
Additionally, each facet definition element can be uniquely
addressed via a URI constructed as follows:
1) the base URI is the URI of the XML Schema namespace
2) the fragment identifier is the name of the facet
For example, to address the maxInclusive facet, the URI is:
http://www.w3.org/2001/XMLSchema#maxInclusive
Additionally, each facet usage in a built-in datatype definition
can be uniquely addressed via a URI constructed as follows:
1) the base URI is the URI of the XML Schema namespace
2) the fragment identifier is the name of the datatype, followed
by a period (".") followed by the name of the facet
For example, to address the usage of the maxInclusive facet in
the definition of int, the URI is:
http://www.w3.org/2001/XMLSchema#int.maxInclusive
</xs:documentation>
</xs:annotation>
<xs:simpleType name="string" id="string">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="length"/>
<hfp:hasFacet name="minLength"/>
<hfp:hasFacet name="maxLength"/>
<hfp:hasFacet name="pattern"/>
<hfp:hasFacet name="enumeration"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasProperty name="ordered" value="false"/>
<hfp:hasProperty name="bounded" value="false"/>
<hfp:hasProperty name="cardinality" value="countably infinite"/>
<hfp:hasProperty name="numeric" value="false"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#string"/>
</xs:annotation>
<xs:restriction base="xs:anySimpleType">
<xs:whiteSpace value="preserve" id="string.preserve"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="boolean" id="boolean">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="pattern"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasProperty name="ordered" value="false"/>
<hfp:hasProperty name="bounded" value="false"/>
<hfp:hasProperty name="cardinality" value="finite"/>
<hfp:hasProperty name="numeric" value="false"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#boolean"/>
</xs:annotation>
<xs:restriction base="xs:anySimpleType">
<xs:whiteSpace value="collapse" fixed="true"
id="boolean.whiteSpace"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="float" id="float">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="pattern"/>
<hfp:hasFacet name="enumeration"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasFacet name="maxInclusive"/>
<hfp:hasFacet name="maxExclusive"/>
<hfp:hasFacet name="minInclusive"/>
<hfp:hasFacet name="minExclusive"/>
<hfp:hasProperty name="ordered" value="total"/>
<hfp:hasProperty name="bounded" value="true"/>
<hfp:hasProperty name="cardinality" value="finite"/>
<hfp:hasProperty name="numeric" value="true"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#float"/>
</xs:annotation>
<xs:restriction base="xs:anySimpleType">
<xs:whiteSpace value="collapse" fixed="true"
id="float.whiteSpace"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="double" id="double">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="pattern"/>
<hfp:hasFacet name="enumeration"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasFacet name="maxInclusive"/>
<hfp:hasFacet name="maxExclusive"/>
<hfp:hasFacet name="minInclusive"/>
<hfp:hasFacet name="minExclusive"/>
<hfp:hasProperty name="ordered" value="total"/>
<hfp:hasProperty name="bounded" value="true"/>
<hfp:hasProperty name="cardinality" value="finite"/>
<hfp:hasProperty name="numeric" value="true"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#double"/>
</xs:annotation>
<xs:restriction base="xs:anySimpleType">
<xs:whiteSpace value="collapse" fixed="true"
id="double.whiteSpace"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="decimal" id="decimal">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="totalDigits"/>
<hfp:hasFacet name="fractionDigits"/>
<hfp:hasFacet name="pattern"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasFacet name="enumeration"/>
<hfp:hasFacet name="maxInclusive"/>
<hfp:hasFacet name="maxExclusive"/>
<hfp:hasFacet name="minInclusive"/>
<hfp:hasFacet name="minExclusive"/>
<hfp:hasProperty name="ordered" value="total"/>
<hfp:hasProperty name="bounded" value="false"/>
<hfp:hasProperty name="cardinality"
value="countably infinite"/>
<hfp:hasProperty name="numeric" value="true"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#decimal"/>
</xs:annotation>
<xs:restriction base="xs:anySimpleType">
<xs:whiteSpace value="collapse" fixed="true"
id="decimal.whiteSpace"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="duration" id="duration">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="pattern"/>
<hfp:hasFacet name="enumeration"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasFacet name="maxInclusive"/>
<hfp:hasFacet name="maxExclusive"/>
<hfp:hasFacet name="minInclusive"/>
<hfp:hasFacet name="minExclusive"/>
<hfp:hasProperty name="ordered" value="partial"/>
<hfp:hasProperty name="bounded" value="false"/>
<hfp:hasProperty name="cardinality"
value="countably infinite"/>
<hfp:hasProperty name="numeric" value="false"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#duration"/>
</xs:annotation>
<xs:restriction base="xs:anySimpleType">
<xs:whiteSpace value="collapse" fixed="true"
id="duration.whiteSpace"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="dateTime" id="dateTime">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="pattern"/>
<hfp:hasFacet name="enumeration"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasFacet name="maxInclusive"/>
<hfp:hasFacet name="maxExclusive"/>
<hfp:hasFacet name="minInclusive"/>
<hfp:hasFacet name="minExclusive"/>
<hfp:hasProperty name="ordered" value="partial"/>
<hfp:hasProperty name="bounded" value="false"/>
<hfp:hasProperty name="cardinality"
value="countably infinite"/>
<hfp:hasProperty name="numeric" value="false"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#dateTime"/>
</xs:annotation>
<xs:restriction base="xs:anySimpleType">
<xs:whiteSpace value="collapse" fixed="true"
id="dateTime.whiteSpace"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="time" id="time">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="pattern"/>
<hfp:hasFacet name="enumeration"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasFacet name="maxInclusive"/>
<hfp:hasFacet name="maxExclusive"/>
<hfp:hasFacet name="minInclusive"/>
<hfp:hasFacet name="minExclusive"/>
<hfp:hasProperty name="ordered" value="partial"/>
<hfp:hasProperty name="bounded" value="false"/>
<hfp:hasProperty name="cardinality"
value="countably infinite"/>
<hfp:hasProperty name="numeric" value="false"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#time"/>
</xs:annotation>
<xs:restriction base="xs:anySimpleType">
<xs:whiteSpace value="collapse" fixed="true"
id="time.whiteSpace"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="date" id="date">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="pattern"/>
<hfp:hasFacet name="enumeration"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasFacet name="maxInclusive"/>
<hfp:hasFacet name="maxExclusive"/>
<hfp:hasFacet name="minInclusive"/>
<hfp:hasFacet name="minExclusive"/>
<hfp:hasProperty name="ordered" value="partial"/>
<hfp:hasProperty name="bounded" value="false"/>
<hfp:hasProperty name="cardinality"
value="countably infinite"/>
<hfp:hasProperty name="numeric" value="false"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#date"/>
</xs:annotation>
<xs:restriction base="xs:anySimpleType">
<xs:whiteSpace value="collapse" fixed="true"
id="date.whiteSpace"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="gYearMonth" id="gYearMonth">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="pattern"/>
<hfp:hasFacet name="enumeration"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasFacet name="maxInclusive"/>
<hfp:hasFacet name="maxExclusive"/>
<hfp:hasFacet name="minInclusive"/>
<hfp:hasFacet name="minExclusive"/>
<hfp:hasProperty name="ordered" value="partial"/>
<hfp:hasProperty name="bounded" value="false"/>
<hfp:hasProperty name="cardinality"
value="countably infinite"/>
<hfp:hasProperty name="numeric" value="false"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#gYearMonth"/>
</xs:annotation>
<xs:restriction base="xs:anySimpleType">
<xs:whiteSpace value="collapse" fixed="true"
id="gYearMonth.whiteSpace"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="gYear" id="gYear">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="pattern"/>
<hfp:hasFacet name="enumeration"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasFacet name="maxInclusive"/>
<hfp:hasFacet name="maxExclusive"/>
<hfp:hasFacet name="minInclusive"/>
<hfp:hasFacet name="minExclusive"/>
<hfp:hasProperty name="ordered" value="partial"/>
<hfp:hasProperty name="bounded" value="false"/>
<hfp:hasProperty name="cardinality"
value="countably infinite"/>
<hfp:hasProperty name="numeric" value="false"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#gYear"/>
</xs:annotation>
<xs:restriction base="xs:anySimpleType">
<xs:whiteSpace value="collapse" fixed="true"
id="gYear.whiteSpace"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="gMonthDay" id="gMonthDay">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="pattern"/>
<hfp:hasFacet name="enumeration"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasFacet name="maxInclusive"/>
<hfp:hasFacet name="maxExclusive"/>
<hfp:hasFacet name="minInclusive"/>
<hfp:hasFacet name="minExclusive"/>
<hfp:hasProperty name="ordered" value="partial"/>
<hfp:hasProperty name="bounded" value="false"/>
<hfp:hasProperty name="cardinality"
value="countably infinite"/>
<hfp:hasProperty name="numeric" value="false"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#gMonthDay"/>
</xs:annotation>
<xs:restriction base="xs:anySimpleType">
<xs:whiteSpace value="collapse" fixed="true"
id="gMonthDay.whiteSpace"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="gDay" id="gDay">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="pattern"/>
<hfp:hasFacet name="enumeration"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasFacet name="maxInclusive"/>
<hfp:hasFacet name="maxExclusive"/>
<hfp:hasFacet name="minInclusive"/>
<hfp:hasFacet name="minExclusive"/>
<hfp:hasProperty name="ordered" value="partial"/>
<hfp:hasProperty name="bounded" value="false"/>
<hfp:hasProperty name="cardinality"
value="countably infinite"/>
<hfp:hasProperty name="numeric" value="false"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#gDay"/>
</xs:annotation>
<xs:restriction base="xs:anySimpleType">
<xs:whiteSpace value="collapse" fixed="true"
id="gDay.whiteSpace"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="gMonth" id="gMonth">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="pattern"/>
<hfp:hasFacet name="enumeration"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasFacet name="maxInclusive"/>
<hfp:hasFacet name="maxExclusive"/>
<hfp:hasFacet name="minInclusive"/>
<hfp:hasFacet name="minExclusive"/>
<hfp:hasProperty name="ordered" value="partial"/>
<hfp:hasProperty name="bounded" value="false"/>
<hfp:hasProperty name="cardinality"
value="countably infinite"/>
<hfp:hasProperty name="numeric" value="false"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#gMonth"/>
</xs:annotation>
<xs:restriction base="xs:anySimpleType">
<xs:whiteSpace value="collapse" fixed="true"
id="gMonth.whiteSpace"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="hexBinary" id="hexBinary">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="length"/>
<hfp:hasFacet name="minLength"/>
<hfp:hasFacet name="maxLength"/>
<hfp:hasFacet name="pattern"/>
<hfp:hasFacet name="enumeration"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasProperty name="ordered" value="false"/>
<hfp:hasProperty name="bounded" value="false"/>
<hfp:hasProperty name="cardinality"
value="countably infinite"/>
<hfp:hasProperty name="numeric" value="false"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#binary"/>
</xs:annotation>
<xs:restriction base="xs:anySimpleType">
<xs:whiteSpace value="collapse" fixed="true"
id="hexBinary.whiteSpace"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="base64Binary" id="base64Binary">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="length"/>
<hfp:hasFacet name="minLength"/>
<hfp:hasFacet name="maxLength"/>
<hfp:hasFacet name="pattern"/>
<hfp:hasFacet name="enumeration"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasProperty name="ordered" value="false"/>
<hfp:hasProperty name="bounded" value="false"/>
<hfp:hasProperty name="cardinality"
value="countably infinite"/>
<hfp:hasProperty name="numeric" value="false"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#base64Binary"/>
</xs:annotation>
<xs:restriction base="xs:anySimpleType">
<xs:whiteSpace value="collapse" fixed="true"
id="base64Binary.whiteSpace"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="anyURI" id="anyURI">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="length"/>
<hfp:hasFacet name="minLength"/>
<hfp:hasFacet name="maxLength"/>
<hfp:hasFacet name="pattern"/>
<hfp:hasFacet name="enumeration"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasProperty name="ordered" value="false"/>
<hfp:hasProperty name="bounded" value="false"/>
<hfp:hasProperty name="cardinality"
value="countably infinite"/>
<hfp:hasProperty name="numeric" value="false"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#anyURI"/>
</xs:annotation>
<xs:restriction base="xs:anySimpleType">
<xs:whiteSpace value="collapse" fixed="true"
id="anyURI.whiteSpace"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="QName" id="QName">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="length"/>
<hfp:hasFacet name="minLength"/>
<hfp:hasFacet name="maxLength"/>
<hfp:hasFacet name="pattern"/>
<hfp:hasFacet name="enumeration"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasProperty name="ordered" value="false"/>
<hfp:hasProperty name="bounded" value="false"/>
<hfp:hasProperty name="cardinality"
value="countably infinite"/>
<hfp:hasProperty name="numeric" value="false"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#QName"/>
</xs:annotation>
<xs:restriction base="xs:anySimpleType">
<xs:whiteSpace value="collapse" fixed="true"
id="QName.whiteSpace"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="NOTATION" id="NOTATION">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="length"/>
<hfp:hasFacet name="minLength"/>
<hfp:hasFacet name="maxLength"/>
<hfp:hasFacet name="pattern"/>
<hfp:hasFacet name="enumeration"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasProperty name="ordered" value="false"/>
<hfp:hasProperty name="bounded" value="false"/>
<hfp:hasProperty name="cardinality"
value="countably infinite"/>
<hfp:hasProperty name="numeric" value="false"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#NOTATION"/>
<xs:documentation>
NOTATION cannot be used directly in a schema; rather a type
must be derived from it by specifying at least one enumeration
facet whose value is the name of a NOTATION declared in the
schema.
</xs:documentation>
</xs:annotation>
<xs:restriction base="xs:anySimpleType">
<xs:whiteSpace value="collapse" fixed="true"
id="NOTATION.whiteSpace"/>
</xs:restriction>
</xs:simpleType>
<xs:annotation>
<xs:documentation>
Now the derived primitive types
</xs:documentation>
</xs:annotation>
<xs:simpleType name="normalizedString" id="normalizedString">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#normalizedString"/>
</xs:annotation>
<xs:restriction base="xs:string">
<xs:whiteSpace value="replace"
id="normalizedString.whiteSpace"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="token" id="token">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#token"/>
</xs:annotation>
<xs:restriction base="xs:normalizedString">
<xs:whiteSpace value="collapse" id="token.whiteSpace"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="language" id="language">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#language"/>
</xs:annotation>
<xs:restriction base="xs:token">
<xs:pattern
value="([a-zA-Z]{2}|[iI]-[a-zA-Z]+|[xX]-[a-zA-Z]{1,8})(-[a-zA-Z]{1,8})*"
id="language.pattern">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/REC-xml#NT-LanguageID">
pattern specifies the content of section 2.12 of XML 1.0e2
and RFC 1766
</xs:documentation>
</xs:annotation>
</xs:pattern>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="IDREFS" id="IDREFS">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="length"/>
<hfp:hasFacet name="minLength"/>
<hfp:hasFacet name="maxLength"/>
<hfp:hasFacet name="enumeration"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasProperty name="ordered" value="false"/>
<hfp:hasProperty name="bounded" value="false"/>
<hfp:hasProperty name="cardinality"
value="countably infinite"/>
<hfp:hasProperty name="numeric" value="false"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#IDREFS"/>
</xs:annotation>
<xs:restriction>
<xs:simpleType>
<xs:list itemType="xs:IDREF"/>
</xs:simpleType>
<xs:minLength value="1" id="IDREFS.minLength"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="ENTITIES" id="ENTITIES">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="length"/>
<hfp:hasFacet name="minLength"/>
<hfp:hasFacet name="maxLength"/>
<hfp:hasFacet name="enumeration"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasProperty name="ordered" value="false"/>
<hfp:hasProperty name="bounded" value="false"/>
<hfp:hasProperty name="cardinality"
value="countably infinite"/>
<hfp:hasProperty name="numeric" value="false"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#ENTITIES"/>
</xs:annotation>
<xs:restriction>
<xs:simpleType>
<xs:list itemType="xs:ENTITY"/>
</xs:simpleType>
<xs:minLength value="1" id="ENTITIES.minLength"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="NMTOKEN" id="NMTOKEN">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#NMTOKEN"/>
</xs:annotation>
<xs:restriction base="xs:token">
<xs:pattern value="\c+" id="NMTOKEN.pattern">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/REC-xml#NT-Nmtoken">
pattern matches production 7 from the XML spec
</xs:documentation>
</xs:annotation>
</xs:pattern>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="NMTOKENS" id="NMTOKENS">
<xs:annotation>
<xs:appinfo>
<hfp:hasFacet name="length"/>
<hfp:hasFacet name="minLength"/>
<hfp:hasFacet name="maxLength"/>
<hfp:hasFacet name="enumeration"/>
<hfp:hasFacet name="whiteSpace"/>
<hfp:hasProperty name="ordered" value="false"/>
<hfp:hasProperty name="bounded" value="false"/>
<hfp:hasProperty name="cardinality"
value="countably infinite"/>
<hfp:hasProperty name="numeric" value="false"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#NMTOKENS"/>
</xs:annotation>
<xs:restriction>
<xs:simpleType>
<xs:list itemType="xs:NMTOKEN"/>
</xs:simpleType>
<xs:minLength value="1" id="NMTOKENS.minLength"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="Name" id="Name">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#Name"/>
</xs:annotation>
<xs:restriction base="xs:token">
<xs:pattern value="\i\c*" id="Name.pattern">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/REC-xml#NT-Name">
pattern matches production 5 from the XML spec
</xs:documentation>
</xs:annotation>
</xs:pattern>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="NCName" id="NCName">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#NCName"/>
</xs:annotation>
<xs:restriction base="xs:Name">
<xs:pattern value="[\i-[:]][\c-[:]]*" id="NCName.pattern">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/REC-xml-names/#NT-NCName">
pattern matches production 4 from the Namespaces in XML spec
</xs:documentation>
</xs:annotation>
</xs:pattern>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="ID" id="ID">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#ID"/>
</xs:annotation>
<xs:restriction base="xs:NCName"/>
</xs:simpleType>
<xs:simpleType name="IDREF" id="IDREF">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#IDREF"/>
</xs:annotation>
<xs:restriction base="xs:NCName"/>
</xs:simpleType>
<xs:simpleType name="ENTITY" id="ENTITY">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#ENTITY"/>
</xs:annotation>
<xs:restriction base="xs:NCName"/>
</xs:simpleType>
<xs:simpleType name="integer" id="integer">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#integer"/>
</xs:annotation>
<xs:restriction base="xs:decimal">
<xs:fractionDigits value="0" fixed="true" id="integer.fractionDigits"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="nonPositiveInteger" id="nonPositiveInteger">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#nonPositiveInteger"/>
</xs:annotation>
<xs:restriction base="xs:integer">
<xs:maxInclusive value="0" id="nonPositiveInteger.maxInclusive"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="negativeInteger" id="negativeInteger">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#negativeInteger"/>
</xs:annotation>
<xs:restriction base="xs:nonPositiveInteger">
<xs:maxInclusive value="-1" id="negativeInteger.maxInclusive"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="long" id="long">
<xs:annotation>
<xs:appinfo>
<hfp:hasProperty name="bounded" value="true"/>
<hfp:hasProperty name="cardinality" value="finite"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#long"/>
</xs:annotation>
<xs:restriction base="xs:integer">
<xs:minInclusive value="-9223372036854775808" id="long.minInclusive"/>
<xs:maxInclusive value="9223372036854775807" id="long.maxInclusive"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="int" id="int">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#int"/>
</xs:annotation>
<xs:restriction base="xs:long">
<xs:minInclusive value="-2147483648" id="int.minInclusive"/>
<xs:maxInclusive value="2147483647" id="int.maxInclusive"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="short" id="short">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#short"/>
</xs:annotation>
<xs:restriction base="xs:int">
<xs:minInclusive value="-32768" id="short.minInclusive"/>
<xs:maxInclusive value="32767" id="short.maxInclusive"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="byte" id="byte">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#byte"/>
</xs:annotation>
<xs:restriction base="xs:short">
<xs:minInclusive value="-128" id="byte.minInclusive"/>
<xs:maxInclusive value="127" id="byte.maxInclusive"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="nonNegativeInteger" id="nonNegativeInteger">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#nonNegativeInteger"/>
</xs:annotation>
<xs:restriction base="xs:integer">
<xs:minInclusive value="0" id="nonNegativeInteger.minInclusive"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="unsignedLong" id="unsignedLong">
<xs:annotation>
<xs:appinfo>
<hfp:hasProperty name="bounded" value="true"/>
<hfp:hasProperty name="cardinality" value="finite"/>
</xs:appinfo>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#unsignedLong"/>
</xs:annotation>
<xs:restriction base="xs:nonNegativeInteger">
<xs:maxInclusive value="18446744073709551615"
id="unsignedLong.maxInclusive"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="unsignedInt" id="unsignedInt">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#unsignedInt"/>
</xs:annotation>
<xs:restriction base="xs:unsignedLong">
<xs:maxInclusive value="4294967295"
id="unsignedInt.maxInclusive"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="unsignedShort" id="unsignedShort">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#unsignedShort"/>
</xs:annotation>
<xs:restriction base="xs:unsignedInt">
<xs:maxInclusive value="65535"
id="unsignedShort.maxInclusive"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="unsignedByte" id="unsignedBtype">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#unsignedByte"/>
</xs:annotation>
<xs:restriction base="xs:unsignedShort">
<xs:maxInclusive value="255" id="unsignedByte.maxInclusive"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="positiveInteger" id="positiveInteger">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#positiveInteger"/>
</xs:annotation>
<xs:restriction base="xs:nonNegativeInteger">
<xs:minInclusive value="1" id="positiveInteger.minInclusive"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="derivationControl">
<xs:annotation>
<xs:documentation>
A utility type, not for public use</xs:documentation>
</xs:annotation>
<xs:restriction base="xs:NMTOKEN">
<xs:enumeration value="substitution"/>
<xs:enumeration value="extension"/>
<xs:enumeration value="restriction"/>
<xs:enumeration value="list"/>
<xs:enumeration value="union"/>
</xs:restriction>
</xs:simpleType>
<xs:group name="simpleDerivation">
<xs:choice>
<xs:element ref="xs:restriction"/>
<xs:element ref="xs:list"/>
<xs:element ref="xs:union"/>
</xs:choice>
</xs:group>
<xs:simpleType name="simpleDerivationSet">
<xs:annotation>
<xs:documentation>
#all or (possibly empty) subset of {restriction, union, list}
</xs:documentation>
<xs:documentation>
A utility type, not for public use</xs:documentation>
</xs:annotation>
<xs:union>
<xs:simpleType>
<xs:restriction base="xs:token">
<xs:enumeration value="#all"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType>
<xs:restriction base="xs:derivationControl">
<xs:enumeration value="list"/>
<xs:enumeration value="union"/>
<xs:enumeration value="restriction"/>
</xs:restriction>
</xs:simpleType>
</xs:union>
</xs:simpleType>
<xs:complexType name="simpleType" abstract="true">
<xs:complexContent>
<xs:extension base="xs:annotated">
<xs:group ref="xs:simpleDerivation"/>
<xs:attribute name="final" type="xs:simpleDerivationSet"/>
<xs:attribute name="name" type="xs:NCName">
<xs:annotation>
<xs:documentation>
Can be restricted to required or forbidden
</xs:documentation>
</xs:annotation>
</xs:attribute>
</xs:extension>
</xs:complexContent>
</xs:complexType>
<xs:complexType name="topLevelSimpleType">
<xs:complexContent>
<xs:restriction base="xs:simpleType">
<xs:sequence>
<xs:element ref="xs:annotation" minOccurs="0"/>
<xs:group ref="xs:simpleDerivation"/>
</xs:sequence>
<xs:attribute name="name" use="required"
type="xs:NCName">
<xs:annotation>
<xs:documentation>
Required at the top level
</xs:documentation>
</xs:annotation>
</xs:attribute>
</xs:restriction>
</xs:complexContent>
</xs:complexType>
<xs:complexType name="localSimpleType">
<xs:complexContent>
<xs:restriction base="xs:simpleType">
<xs:sequence>
<xs:element ref="xs:annotation" minOccurs="0"/>
<xs:group ref="xs:simpleDerivation"/>
</xs:sequence>
<xs:attribute name="name" use="prohibited">
<xs:annotation>
<xs:documentation>
Forbidden when nested
</xs:documentation>
</xs:annotation>
</xs:attribute>
<xs:attribute name="final" use="prohibited"/>
</xs:restriction>
</xs:complexContent>
</xs:complexType>
<xs:element name="simpleType" type="xs:topLevelSimpleType" id="simpleType">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#element-simpleType"/>
</xs:annotation>
</xs:element>
<xs:group name="facets">
<xs:annotation>
<xs:documentation>
We should use a substitution group for facets, but
that's ruled out because it would allow users to
add their own, which we're not ready for yet.
</xs:documentation>
</xs:annotation>
<xs:choice>
<xs:element ref="xs:minExclusive"/>
<xs:element ref="xs:minInclusive"/>
<xs:element ref="xs:maxExclusive"/>
<xs:element ref="xs:maxInclusive"/>
<xs:element ref="xs:totalDigits"/>
<xs:element ref="xs:fractionDigits"/>
<xs:element ref="xs:length"/>
<xs:element ref="xs:minLength"/>
<xs:element ref="xs:maxLength"/>
<xs:element ref="xs:enumeration"/>
<xs:element ref="xs:whiteSpace"/>
<xs:element ref="xs:pattern"/>
</xs:choice>
</xs:group>
<xs:group name="simpleRestrictionModel">
<xs:sequence>
<xs:element name="simpleType" type="xs:localSimpleType" minOccurs="0"/>
<xs:group ref="xs:facets" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
</xs:group>
<xs:element name="restriction" id="restriction">
<xs:complexType>
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#element-restriction">
base attribute and simpleType child are mutually
exclusive, but one or other is required
</xs:documentation>
</xs:annotation>
<xs:complexContent>
<xs:extension base="xs:annotated">
<xs:group ref="xs:simpleRestrictionModel"/>
<xs:attribute name="base" type="xs:QName" use="optional"/>
</xs:extension>
</xs:complexContent>
</xs:complexType>
</xs:element>
<xs:element name="list" id="list">
<xs:complexType>
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#element-list">
itemType attribute and simpleType child are mutually
exclusive, but one or other is required
</xs:documentation>
</xs:annotation>
<xs:complexContent>
<xs:extension base="xs:annotated">
<xs:sequence>
<xs:element name="simpleType" type="xs:localSimpleType"
minOccurs="0"/>
</xs:sequence>
<xs:attribute name="itemType" type="xs:QName" use="optional"/>
</xs:extension>
</xs:complexContent>
</xs:complexType>
</xs:element>
<xs:element name="union" id="union">
<xs:complexType>
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#element-union">
memberTypes attribute must be non-empty or there must be
at least one simpleType child
</xs:documentation>
</xs:annotation>
<xs:complexContent>
<xs:extension base="xs:annotated">
<xs:sequence>
<xs:element name="simpleType" type="xs:localSimpleType"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="memberTypes" use="optional">
<xs:simpleType>
<xs:list itemType="xs:QName"/>
</xs:simpleType>
</xs:attribute>
</xs:extension>
</xs:complexContent>
</xs:complexType>
</xs:element>
<xs:complexType name="facet">
<xs:complexContent>
<xs:extension base="xs:annotated">
<xs:attribute name="value" use="required"/>
<xs:attribute name="fixed" type="xs:boolean" use="optional"
default="false"/>
</xs:extension>
</xs:complexContent>
</xs:complexType>
<xs:complexType name="noFixedFacet">
<xs:complexContent>
<xs:restriction base="xs:facet">
<xs:sequence>
<xs:element ref="xs:annotation" minOccurs="0"/>
</xs:sequence>
<xs:attribute name="fixed" use="prohibited"/>
</xs:restriction>
</xs:complexContent>
</xs:complexType>
<xs:element name="minExclusive" id="minExclusive" type="xs:facet">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#element-minExclusive"/>
</xs:annotation>
</xs:element>
<xs:element name="minInclusive" id="minInclusive" type="xs:facet">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#element-minInclusive"/>
</xs:annotation>
</xs:element>
<xs:element name="maxExclusive" id="maxExclusive" type="xs:facet">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#element-maxExclusive"/>
</xs:annotation>
</xs:element>
<xs:element name="maxInclusive" id="maxInclusive" type="xs:facet">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#element-maxInclusive"/>
</xs:annotation>
</xs:element>
<xs:complexType name="numFacet">
<xs:complexContent>
<xs:restriction base="xs:facet">
<xs:sequence>
<xs:element ref="xs:annotation" minOccurs="0"/>
</xs:sequence>
<xs:attribute name="value" type="xs:nonNegativeInteger" use="required"/>
</xs:restriction>
</xs:complexContent>
</xs:complexType>
<xs:element name="totalDigits" id="totalDigits">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#element-totalDigits"/>
</xs:annotation>
<xs:complexType>
<xs:complexContent>
<xs:restriction base="xs:numFacet">
<xs:sequence>
<xs:element ref="xs:annotation" minOccurs="0"/>
</xs:sequence>
<xs:attribute name="value" type="xs:positiveInteger" use="required"/>
</xs:restriction>
</xs:complexContent>
</xs:complexType>
</xs:element>
<xs:element name="fractionDigits" id="fractionDigits" type="xs:numFacet">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#element-fractionDigits"/>
</xs:annotation>
</xs:element>
<xs:element name="length" id="length" type="xs:numFacet">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#element-length"/>
</xs:annotation>
</xs:element>
<xs:element name="minLength" id="minLength" type="xs:numFacet">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#element-minLength"/>
</xs:annotation>
</xs:element>
<xs:element name="maxLength" id="maxLength" type="xs:numFacet">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#element-maxLength"/>
</xs:annotation>
</xs:element>
<xs:element name="enumeration" id="enumeration" type="xs:noFixedFacet">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#element-enumeration"/>
</xs:annotation>
</xs:element>
<xs:element name="whiteSpace" id="whiteSpace">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#element-whiteSpace"/>
</xs:annotation>
<xs:complexType>
<xs:complexContent>
<xs:restriction base="xs:facet">
<xs:sequence>
<xs:element ref="xs:annotation" minOccurs="0"/>
</xs:sequence>
<xs:attribute name="value" use="required">
<xs:simpleType>
<xs:restriction base="xs:NMTOKEN">
<xs:enumeration value="preserve"/>
<xs:enumeration value="replace"/>
<xs:enumeration value="collapse"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:restriction>
</xs:complexContent>
</xs:complexType>
</xs:element>
<xs:element name="pattern" id="pattern" type="xs:noFixedFacet">
<xs:annotation>
<xs:documentation
source="http://www.w3.org/TR/xmlschema-2/#element-pattern"/>
</xs:annotation>
</xs:element>
</xs:schema>
B DTD for Datatype Definitions
(non-normative)
<!--
DTD for XML Schemas: Part 2: Datatypes
Id: datatypes.dtd,v 1.23 2001/03/16 17:36:30 ht Exp
Note this DTD is NOT normative, or even definitive.
-->
<!--
This DTD cannot be used on its own, it is intended
only for incorporation in XMLSchema.dtd, q.v.
-->
<!-- Define all the element names, with optional prefix -->
<!ENTITY % simpleType "%p;simpleType">
<!ENTITY % restriction "%p;restriction">
<!ENTITY % list "%p;list">
<!ENTITY % union "%p;union">
<!ENTITY % maxExclusive "%p;maxExclusive">
<!ENTITY % minExclusive "%p;minExclusive">
<!ENTITY % maxInclusive "%p;maxInclusive">
<!ENTITY % minInclusive "%p;minInclusive">
<!ENTITY % totalDigits "%p;totalDigits">
<!ENTITY % fractionDigits "%p;fractionDigits">
<!ENTITY % length "%p;length">
<!ENTITY % minLength "%p;minLength">
<!ENTITY % maxLength "%p;maxLength">
<!ENTITY % enumeration "%p;enumeration">
<!ENTITY % whiteSpace "%p;whiteSpace">
<!ENTITY % pattern "%p;pattern">
<!--
Customisation entities for the ATTLIST of each element
type. Define one of these if your schema takes advantage
of the anyAttribute='##other' in the schema for schemas
-->
<!ENTITY % simpleTypeAttrs "">
<!ENTITY % restrictionAttrs "">
<!ENTITY % listAttrs "">
<!ENTITY % unionAttrs "">
<!ENTITY % maxExclusiveAttrs "">
<!ENTITY % minExclusiveAttrs "">
<!ENTITY % maxInclusiveAttrs "">
<!ENTITY % minInclusiveAttrs "">
<!ENTITY % totalDigitsAttrs "">
<!ENTITY % fractionDigitsAttrs "">
<!ENTITY % lengthAttrs "">
<!ENTITY % minLengthAttrs "">
<!ENTITY % maxLengthAttrs "">
<!ENTITY % enumerationAttrs "">
<!ENTITY % whiteSpaceAttrs "">
<!ENTITY % patternAttrs "">
<!-- Define some entities for informative use as attribute
types -->
<!ENTITY % URIref "CDATA">
<!ENTITY % XPathExpr "CDATA">
<!ENTITY % QName "NMTOKEN">
<!ENTITY % QNames "NMTOKENS">
<!ENTITY % NCName "NMTOKEN">
<!ENTITY % nonNegativeInteger "NMTOKEN">
<!ENTITY % boolean "(true|false)">
<!ENTITY % simpleDerivationSet "CDATA">
<!--
#all or space-separated list drawn from derivationChoice
-->
<!--
Note that the use of 'facet' below is less restrictive
than is really intended: There should in fact be no
more than one of each of minInclusive, minExclusive,
maxInclusive, maxExclusive, totalDigits, fractionDigits,
length, maxLength, minLength within datatype,
and the min- and max- variants of Inclusive and Exclusive
are mutually exclusive. On the other hand, pattern and
enumeration may repeat.
-->
<!ENTITY % minBound "(%minInclusive; | %minExclusive;)">
<!ENTITY % maxBound "(%maxInclusive; | %maxExclusive;)">
<!ENTITY % bounds "%minBound; | %maxBound;">
<!ENTITY % numeric "%totalDigits; | %fractionDigits;">
<!ENTITY % ordered "%bounds; | %numeric;">
<!ENTITY % unordered
"%pattern; | %enumeration; | %whiteSpace; | %length; |
%maxLength; | %minLength;">
<!ENTITY % facet "%ordered; | %unordered;">
<!ENTITY % facetAttr
"value CDATA #REQUIRED
id ID #IMPLIED">
<!ENTITY % fixedAttr "fixed %boolean; #IMPLIED">
<!ENTITY % facetModel "(%annotation;)?">
<!ELEMENT %simpleType;
((%annotation;)?, (%restriction; | %list; | %union;))>
<!ATTLIST %simpleType;
name %NCName; #IMPLIED
final %simpleDerivationSet; #IMPLIED
id ID #IMPLIED
%simpleTypeAttrs;>
<!-- name is required at top level -->
<!ELEMENT %restriction; ((%annotation;)?,
(%restriction1; |
((%simpleType;)?,(%facet;)*)),
(%attrDecls;))>
<!ATTLIST %restriction;
base %QName; #IMPLIED
id ID #IMPLIED
%restrictionAttrs;>
<!--
base and simpleType child are mutually exclusive,
one is required.
restriction is shared between simpleType and
simpleContent and complexContent (in XMLSchema.xsd).
restriction1 is for the latter cases, when this
is restricting a complex type, as is attrDecls.
-->
<!ELEMENT %list; ((%annotation;)?,(%simpleType;)?)>
<!ATTLIST %list;
itemType %QName; #IMPLIED
id ID #IMPLIED
%listAttrs;>
<!--
itemType and simpleType child are mutually exclusive,
one is required
-->
<!ELEMENT %union; ((%annotation;)?,(%simpleType;)*)>
<!ATTLIST %union;
id ID #IMPLIED
memberTypes %QNames; #IMPLIED
%unionAttrs;>
<!--
At least one item in memberTypes or one simpleType
child is required
-->
<!ELEMENT %maxExclusive; %facetModel;>
<!ATTLIST %maxExclusive;
%facetAttr;
%fixedAttr;
%maxExclusiveAttrs;>
<!ELEMENT %minExclusive; %facetModel;>
<!ATTLIST %minExclusive;
%facetAttr;
%fixedAttr;
%minExclusiveAttrs;>
<!ELEMENT %maxInclusive; %facetModel;>
<!ATTLIST %maxInclusive;
%facetAttr;
%fixedAttr;
%maxInclusiveAttrs;>
<!ELEMENT %minInclusive; %facetModel;>
<!ATTLIST %minInclusive;
%facetAttr;
%fixedAttr;
%minInclusiveAttrs;>
<!ELEMENT %totalDigits; %facetModel;>
<!ATTLIST %totalDigits;
%facetAttr;
%fixedAttr;
%totalDigitsAttrs;>
<!ELEMENT %fractionDigits; %facetModel;>
<!ATTLIST %fractionDigits;
%facetAttr;
%fixedAttr;
%fractionDigitsAttrs;>
<!ELEMENT %length; %facetModel;>
<!ATTLIST %length;
%facetAttr;
%fixedAttr;
%lengthAttrs;>
<!ELEMENT %minLength; %facetModel;>
<!ATTLIST %minLength;
%facetAttr;
%fixedAttr;
%minLengthAttrs;>
<!ELEMENT %maxLength; %facetModel;>
<!ATTLIST %maxLength;
%facetAttr;
%fixedAttr;
%maxLengthAttrs;>
<!-- This one can be repeated -->
<!ELEMENT %enumeration; %facetModel;>
<!ATTLIST %enumeration;
%facetAttr;
%enumerationAttrs;>
<!ELEMENT %whiteSpace; %facetModel;>
<!ATTLIST %whiteSpace;
%facetAttr;
%fixedAttr;
%whiteSpaceAttrs;>
<!-- This one can be repeated -->
<!ELEMENT %pattern; %facetModel;>
<!ATTLIST %pattern;
%facetAttr;
%patternAttrs;>
C Datatypes and Facets
C.1 Fundamental
Facets
The following table shows the values of the fundamental facets for each ·built-in· datatype.
D ISO 8601 Date and Time Formats
D.1 ISO 8601 Conventions
The ·primitive· datatypes duration,
dateTime,
time, date, gYearMonth,
gMonthDay,
gDay, gMonth and
gYear
use lexical formats inspired by [ISO
8601]. This appendix provides more detail on the ISO formats and discusses
some deviations from them for the datatypes defined in this specification.
[ISO
8601] "specifies the representation of dates in the proleptic Gregorian
calendar and times and representations of periods of time". The proleptic
Gregorian calendar includes dates prior to 1582 (the year it came into use as an
ecclesiastical calendar). It should be pointed out that the datatypes described
in this specification do not cover all the types of data covered by [ISO
8601], nor do they support all the lexical representations for those types
of data.
[ISO
8601] lexical formats are described using "pictures" in which characters are
used in place of digits. For the primitive datatypes dateTime,
time, date, gYearMonth,
gMonthDay,
gDay, gMonth and
gYear.
these characters have the following meanings:
- C -- represents a digit used in the thousands and hundreds components, the
"century" component, of the time element "year". Legal values are from 0 to 9.
- Y -- represents a digit used in the tens and units components of the time
element "year". Legal values are from 0 to 9.
- M -- represents a digit used in the time element "month". The two digits
in a MM format can have values from 1 to 12.
- D -- represents a digit used in the time element "day". The two digits in
a DD format can have values from 1 to 28 if the month value equals 2, 1 to 29
if the month value equals 2 and the year is a leap year, 1 to 30 if the month
value equals 4, 6, 9 or 11, and 1 to 31 if the month value equals 1, 3, 5, 7,
8, 10 or 12.
- h -- represents a digit used in the time element "hour". The two digits in
a hh format can have values from 0 to 23.
- m -- represents a digit used in the time element "minute". The two digits
in a mm format can have values from 0 to 59.
- s -- represents a digit used in the time element "second". The two digits
in a ss format can have values from 0 to 60. In the formats described in this
specification the whole number of seconds ·may· be followed by decimal
seconds to an arbitrary level of precision. This is represented in the picture
by "ss.sss". A value of 60 or more is allowed only in the case of leap
seconds.
Strictly speaking, a value of 60 or more is not sensible unless the
month and day could represent March 31, June 30, September 30, or December 31
in UTC. Because the leap second is added or subtracted as the last
second of the day in UTC time, the long (or short) minute could occur at other
times in local time. In cases where the leap second is used with an
inappropriate month and day it, and any fractional seconds, should considered
as added or subtracted from the following minute.
For all the information items indicated by the above characters, leading
zeros are required where indicated.
In addition to the above, certain characters are used as designators and
appear as themselves in lexical formats.
- T -- is used as time designator to indicate the start of the
representation of the time of day in dateTime.
- Z -- is used as time-zone designator, immediately (without a space)
following a data element expressing the time of day in Coordinated Universal
Time (UTC) in dateTime,
time,
date,
gYearMonth,
gMonthDay,
gDay,
gMonth,
and gYear.
In the lexical format for duration
the following characters are also used as designators and appear as themselves
in lexical formats:
- P -- is used as the time duration designator, preceding a data element
representing a given duration of time.
- Y -- follows the number of years in a time duration.
- M -- follows the number of months or minutes in a time duration.
- D -- follows the number of days in a time duration.
- H -- follows the number of hours in a time duration.
- S -- follows the number of seconds in a time duration.
The values of the Year, Month, Day, Hour and Minutes components are not
restricted but allow an arbitrary integer. Similarly, the value of the Seconds
component allows an arbitrary decimal. Thus, the lexical format for duration
and datatypes derived from it does not follow the alternative format of §
5.5.3.2.1 of [ISO
8601].
D.2 Truncated and Reduced Formats
[ISO
8601] supports a variety of "truncated" formats in which some of the
characters on the left of specific formats, for example, the century, can be
omitted. Truncated formats are, in general, not permitted for the datatypes
defined in this specification with three exceptions. The time
datatype uses a truncated format for dateTime
which represents an instant of time that recurs every day. Similarly, the gMonthDay
and gDay
datatypes use left-truncated formats for date. The
datatype gMonth
uses a right and left truncated format for date.
[ISO
8601] also supports a variety of "reduced" or right-truncated formats in
which some of the characters to the right of specific formats, such as the time
specification, can be omitted. Right truncated formats are also, in general, not
permitted for the datatypes defined in this specification with the following
exceptions: right-truncated representations of dateTime
are used as lexical representations for date, gMonth, gYear.
D.3 Deviations from ISO 8601 Formats
D.3.1 Sign Allowed
An optional minus sign is allowed immediately preceding, without a space, the
lexical representations for duration,
dateTime,
date, gMonth, gYear.
D.3.2 No Year Zero
The year "0000" is an illegal year value.
E Adding durations to
dateTimes
Given a dateTime
S and a duration
D, this appendix specifies how to compute a dateTime
E where E is the end of the time period with start S and duration D i.e. E = S +
D. Such computations are used, for example, to determine whether a dateTime
is within a specific time period. This appendix also addresses the addition of
durations
to the datatypes date, gYearMonth,
gYear,
gDay and
gMonth,
which can be viewed as a set of dateTimes.
In such cases, the addition is made to the first or starting dateTime
in the set.
This is a logical explanation of the process. Actual implementations are
free to optimize as long as they produce the same results. The calculation
uses the notation S[year] to represent the year field of S, S[month] to
represent the month field, and so on. It also depends on the following
functions:
- fQuotient(a, b) = the greatest integer less than or equal to a/b
- fQuotient(-1,3) = -1
- fQuotient(0,3)...fQuotient(2,3) = 0
- fQuotient(3,3) = 1
- fQuotient(3.123,3) = 1
- modulo(a, b) = a - fQuotient(a,b)*b
- modulo(-1,3) = 2
- modulo(0,3)...modulo(2,3) = 0...2
- modulo(3,3) = 0
- modulo(3.123,3) = 0.123
- fQuotient(a, low, high) = fQuotient(a - low, high - low)
- fQuotient(0, 1, 13) = -1
- fQuotient(1, 1, 13) ... fQuotient(12, 1, 13) = 0
- fQuotient(13, 1, 13) = 1
- fQuotient(13.123, 1, 13) = 1
- modulo(a, low, high) = modulo(a - low, high - low) + low
- modulo(0, 1, 13) = 12
- modulo(1, 1, 13) ... modulo(12, 1, 13) = 1...12
- modulo(13, 1, 13) = 1
- modulo(13.123, 1, 13) = 1.123
- maximumDayInMonthFor(yearValue, monthValue) =
- M := modulo(monthValue, 1, 13)
- Y := yearValue + fQuotient(monthValue, 1, 13)
- Return a value based on M and Y:
| 31 |
M = January, March, May, July, August, October, or
December |
| 30 |
M = April, June, September, or November |
| 29 |
M = February AND (modulo(Y, 400) = 0 OR (modulo(Y, 100) != 0) AND
modulo(Y, 4) = 0) |
| 28 |
Otherwise |
E.1 Algorithm
Essentially, this calculation is equivalent to separating D into
<year,month> and <day,hour,minute,second> fields. The
<year,month> is added to S. If the day is out of range, it is
pinned to be within range. Thus April 31 turns into April 30. Then the
<day,hour,minute,second> is added. This latter addition can cause the year
and month to change.
Leap seconds are handled by the computation by treating them as overflows.
Essentially, a value of 60 seconds in S is treated as if it were a duration of
60 seconds added to S (with a zero seconds field). All calculations thereafter
use 60 seconds per minute.
Thus the addition of either PT1M or PT60S to any dateTime will always produce
the same result. This is a special definition of addition which is designed to
match common practice, and -- most importantly -- be stable over time.
A definition that attempted to take leap-seconds into account would need to
be constantly updated, and could not predict the results of future
implementation's additions. The decision to introduce a leap second in UTC is
the responsibility of the [International
Earth Rotation Service (IERS)]. They make periodic announcements as to when
leap seconds are to be added, but this is not known more than a year in advance.
For more information on leap seconds, see [U.S. Naval
Observatory Time Service Department].
The following is the precise specification. These steps must be followed in
the same order. If a field in D is not specified, it is treated as if it were
zero. If a field in S is not specified, it is treated in the calculation as if
it were the minimum allowed value in that field, however, after the calculation
is concluded, the corresponding field in E is removed (set to unspecified).
- Months (may be modified additionally below)
- temp := S[month] + D[month]
- E[month] := modulo(temp, 1, 13)
- carry := fQuotient(temp, 1, 13)
- Years (may be modified additionally below)
- E[year] := S[year] + D[year] + carry
- Zone
- Seconds
- temp := S[second] + D[second]
- E[second] := modulo(temp, 60)
- carry := fQuotient(temp, 60)
- Minutes
- temp := S[minute] + D[minute] + carry
- E[minute] := modulo(temp, 60)
- carry := fQuotient(temp, 60)
- Hours
- temp := S[hour] + D[hour] + carry
- E[hour] := modulo(temp, 24)
- carry := fQuotient(temp, 24)
- Days
- if S[day] > maximumDayInMonthFor(E[year], E[month])
- tempDays := maximumDayInMonthFor(E[year], E[month])
- else if S[day] < 1
- else
- E[day] := tempDays + D[day] + carry
- START LOOP
- IF E[day] < 1
- E[day] := E[day] + maximumDayInMonthFor(E[year], E[month] - 1)
- carry := -1
- ELSE IF E[day] > maximumDayInMonthFor(E[year], E[month])
- E[day] := E[day] - maximumDayInMonthFor(E[year], E[month])
- carry := 1
- ELSE EXIT LOOP
- temp := E[month] + carry
- E[month] := modulo(temp, 1, 13)
- E[year] := E[year] + fQuotient(temp, 1, 13)
- GOTO START LOOP
Examples:
| dateTime |
duration |
result |
| 2000-01-12T12:13:14Z |
P1Y3M5DT7H10M3.3S |
2001-04-17T19:23:17.3Z |
| 2000-01 |
-P3M |
1999-10 |
| 2000-01-12 |
PT33H |
2000-01-13 |
E.2
Commutativity and Associativity
Time durations are added by simply adding each of their fields, respectively,
without overflow.
The order of addition of durations to instants is significant. For
example, there are cases where:
((dateTime + duration1) + duration2) != ((dateTime + duration2) +
duration1)
Example:
(2000-03-30 + P1D) + P1M = 2000-03-31 + P1M = 2001-04-30
(2000-03-30 + P1M) + P1D = 2000-04-30 + P1D = 2000-05-01
F Regular Expressions
A ·regular expression· R is a sequence of characters that denote a
set of strings L(R). When used to constrain a ·lexical space·, a regular
expression R asserts that only strings in L(R) are valid
literals for values of that type.
[Definition:] A
regular expression is composed from zero or more ·branch·es, separated by
| characters.
| For all ·branch·es S, and
for all ·regular expression·s
T, valid ·regular expression·s
R are: |
Denoting the set of strings L(R) containing: |
| (empty string) |
the set containing just the empty string |
| S |
all strings in L(S) |
| S|T |
all strings in L(S) and all strings in
L(T) |
[Definition:] A
branch consists of zero or more ·piece·s, concatenated together.
| For all ·piece·s S, and for
all ·branch·es T, valid
·branch·es R are:
|
Denoting the set of strings L(R) containing: |
| S |
all strings in L(S) |
| ST |
all strings st with s in L(S) and
t in L(T) |
[Definition:] A
piece is an ·atom·, possibly followed by a
·quantifier·.
| For all ·atom·s S and
non-negative integers n, m such that n <= m, valid
·piece·s R are: |
Denoting the set of strings L(R) containing: |
| S |
all strings in L(S) |
| S? |
the empty string, and all strings in L(S). |
| S* |
All strings in L(S?) and all strings st
with s in L(S*) and t in L(S). ( all
concatenations of zero or more strings from L(S) ) |
| S+ |
All strings st with s in L(S) and
t in L(S*). ( all concatenations of one or more strings
from L(S) ) |
| S{n,m} |
All strings st with s in L(S) and
t in L(S{n-1,m-1}). ( All sequences of at least n, and at
most m, strings from L(S) ) |
| S{n} |
All strings in L(S{n,n}). ( All sequences of
exactly n strings from L(S) ) |
| S{n,} |
All strings in L(S{n}S*) ( All sequences of at least
n, strings from L(S) ) |
| S{0,m} |
All strings st with s in L(S?) and
t in L(S{0,m-1}). ( All sequences of at most m, strings
from L(S) ) |
| S{0,0} |
The set containing only the empty string
|
NOTE: The regular expression language in the Perl
Programming Language [Perl]
does not include a quantifier of the form S{,m), since it is
logically equivalent to S{0,m}. We have, therefore, left this
logical possibility out of the regular expression language defined by this
specification. We welcome further input from implementors and schema authors
on this issue.
[Definition:] A
quantifier is one of ?, *, +,
{n,m} or {n,}, which have the meanings defined in the
table above.
[Definition:] An
atom is either a ·normal character·, a ·character class·, or a
parenthesized ·regular expression·.
[Definition:] A
metacharacter is either ., \, ?,
*, +, {, } (,
), [ or ]. These characters have special
meanings in ·regular expression·s, but can
be escaped to form ·atom·s that denote the sets of
strings containing only themselves, i.e., an escaped ·metacharacter· behaves like a
·normal character·.
[Definition:] A
normal character is any XML character that is not a metacharacter. In ·regular expression·s, a normal
character is an atom that denotes the singleton set of strings containing only
itself.
| Normal Character |
[10] |
Char |
::= |
[^.\?*+()|#x5B#x5D] |
| |
Note that a ·normal character· can be
represented either as itself, or with a character
reference.
F.1
Character Classes
[Definition:] A
character class is an ·atom· R that
identifies a set of characters C(R). The set of strings
L(R) denoted by a character class R contains one single-character
string "c" for each character c in C(R).
A character class is either a ·character class escape· or a ·character class expression·.
[Definition:] A
character class expression is a ·character group· surrounded by
[ and ] characters. For all character groups G,
[G] is a valid character class expression, identifying the set of
characters C([G]) = C(G).
| Character Class
Expression |
|
|
[Definition:] A
character group is either a ·positive character group·, a ·negative character group·, or a
·character class subtraction·.
[Definition:] A
positive character group consists of one or more ·character range·s or ·character class escape·s,
concatenated together. A positive character group identifies the set of
characters containing all of the characters in all of the sets identified by its
constituent ranges or escapes.
[Definition:] A
negative character group is a ·positive character group·
preceded by the ^ character. For all ·positive character group·s
P, ^P is a valid negative character group, and C(^P)
contains all XML characters that are not in C(P).
[Definition:] A
character class subtraction is a ·character class expression·
subtracted from a ·positive character group· or ·negative character group·,
using the - character.
| Character Class
Subtraction |
|
|
For any ·positive character group· or ·negative character group· G, and any ·character class expression· C, G-C is a valid ·character class subtraction·,
identifying the set of all characters in C(G) that are not also in
C(C).
[Definition:] A
character range R identifies a set of characters C(R)
containing all XML characters with UCS code points in a specified range.
A single XML character is a ·character range· that
identifies the set of characters containing only itself. All XML characters are
valid character ranges, except as follows:
A ·character range· ·may· also be written in the
form s-e, identifying the set that contains all XML characters with UCS
code points greater than or equal to the code point of s, but not greater
than the code point of e.
s-e is a valid character range iff:
NOTE: The code point of a ·single character escape· is
the code point of the single character in the set of characters that it
identifies.
F.1.1 Character Class Escapes
[Definition:] A
character class escape is a short sequence of characters that identifies
predefined character class. The valid character class escapes are the ·single character escape·s, the
·multi-character escape·s, and
the ·category escape·s (including
the ·block escape·s).
[Definition:] A
single character escape identifies a set containing a only one character
-- usually because that character is difficult or impossible to write directly
into a ·regular expression·.
| Single Character Escape |
[24] |
SingleCharEsc |
::= |
'\' [nrt\|.?*+(){}#x2D#x5B#x5D#x5E] |
| |
| The valid ·single character escape·s
are: |
Identifying the set of characters C(R) containing:
|
\n |
the newline character (#xA) |
\r |
the return character (#xD) |
\t |
the tab character (#x9) |
\\ |
\ |
\| |
| |
\. |
. |
\- |
- |
\^ |
^ |
\? |
? |
\* |
* |
\+ |
+ |
\{ |
{ |
\} |
} |
\( |
( |
\) |
) |
\[ |
[ |
\] |
] |
[Definition:] [Unicode
Database] specifies a number of possible values for the "General Category"
property and provides mappings from code points to specific character
properties. The set containing all characters that have property X,
can be identified with a category escape \p{X}. The
complement of this set is specified with the category escape
\P{X}. ([\P{X}] = [^\p{X}]).
NOTE: [Unicode
Database] is subject to future revision. For example, the mapping from
code points to character properties might be updated. All ·minimally conforming·
processors ·must· support the character
properties defined in the version of [Unicode
Database] that is current at the time this specification became a W3C
Recommendation. However, implementors are encouraged to support the character
properties defined in any future version.
The following table specifies the recognized values of the "General Category"
property.
| Category |
Property |
Meaning |
| Letters |
L |
All Letters |
| Lu |
uppercase |
| Ll |
lowercase |
| Lt |
titlecase |
| Lm |
modifier |
| Lo |
other |
| |
| Marks |
M |
All Marks |
| Mn |
nonspacing |
| Mc |
spacing combining |
| Me |
enclosing |
| |
| Numbers |
N |
All Numbers |
| Nd |
decimal digit |
| Nl |
letter |
| No |
other |
| |
| Punctuation |
P |
All Punctuation |
| Pc |
connector |
| Pd |
dash |
| Ps |
open |
| Pe |
close |
| Pi |
initial quote (may behave like Ps or Pe depending on usage) |
| Pf |
final quote (may behave like Ps or Pe depending on usage) |
| Po |
other |
| |
| Separators |
Z |
All Separators |
| Zs |
space |
| Zl |
line |
| Zp |
paragraph |
| |
| Symbols |
S |
All Symbols |
| Sm |
math |
| Sc |
currency |
| Sk |
modifier |
| So |
other |
| |
| Other |
C |
All Others |
| Cc |
control |
| Cf |
format |
| Co |
private use |
| Cn |
not assigned |
| Categories |
[28] |
IsCategory |
::= |
Letters
| Marks
| Numbers
| Punctuation
| Separators
| Symbols
| Others
|
|
[29] |
Letters |
::= |
'L' [ultmo]? |
|
[30] |
Marks |
::= |
'M' [nce]? |
|
[31] |
Numbers |
::= |
'N' [dlo]? |
|
[32] |
Punctuation |
::= |
'P' [cdseifo]? |
|
[33] |
Separators |
::= |
'Z' [slp]? |
|
[34] |
Symbols |
::= |
'S' [mcko]? |
|
[35] |
Others |
::= |
'C' [cfon]? |
| |
NOTE: The properties mentioned above exclude the
Cs property. The Cs property identifies "surrogate"
characters, which do not occur at the level of the "character abstraction"
that XML instance documents operate on.
[Definition:] [Unicode
Database] groups code points into a number of blocks such as Basic Latin
(i.e., ASCII), Latin-1 Supplement, Hangul Jamo, CJK Compatibility, etc. The set
containing all characters that have block name X (with all white
space stripped out), can be identified with a block escape
\p{IsX}. The complement of this set is specified with the block
escape \P{IsX}. ([\P{IsX}] =
[^\p{IsX}]).
| Block Escape |
[36] |
IsBlock |
::= |
'Is' [a-zA-Z0-9#x2D]+ |
| |
The following table specifies the recognized block names (for more
information, see the "Blocks.txt" file in [Unicode
Database]).
| Start Code |
End Code |
Block Name |
|
Start Code |
End Code |
Block Name |
| #x0000 |
#x007F |
BasicLatin |
|
#x0080 |
#x00FF |
Latin-1Supplement |
| #x0100 |
#x017F |
LatinExtended-A |
|
#x0180 |
#x024F |
LatinExtended-B |
| #x0250 |
#x02AF |
IPAExtensions |
|
#x02B0 |
#x02FF |
SpacingModifierLetters |
| #x0300 |
#x036F |
CombiningDiacriticalMarks |
|
#x0370 |
#x03FF |
Greek |
| #x0400 |
#x04FF |
Cyrillic |
|
#x0530 |
#x058F |
Armenian |
| #x0590 |
#x05FF |
Hebrew |
|
#x0600 |
#x06FF |
Arabic |
| #x0700 |
#x074F |
Syriac |
|
#x0780 |
#x07BF |
Thaana |
| #x0900 |
#x097F |
Devanagari |
|
#x0980 |
#x09FF |
Bengali |
| #x0A00 |
#x0A7F |
Gurmukhi |
|
#x0A80 |
#x0AFF |
Gujarati |
| #x0B00 |
#x0B7F |
Oriya |
|
#x0B80 |
#x0BFF |
Tamil |
| #x0C00 |
#x0C7F |
Telugu |
|
#x0C80 |
#x0CFF |
Kannada |
| #x0D00 |
#x0D7F |
Malayalam |
|
#x0D80 |
#x0DFF |
Sinhala |
| #x0E00 |
#x0E7F |
Thai |
|
#x0E80 |
#x0EFF |
Lao |
| #x0F00 |
#x0FFF |
Tibetan |
|
#x1000 |
#x109F |
Myanmar |
| #x10A0 |
#x10FF |
Georgian |
|
#x1100 |
#x11FF |
HangulJamo |
| #x1200 |
#x137F |
Ethiopic |
|
#x13A0 |
#x13FF |
Cherokee |
| #x1400 |
#x167F |
UnifiedCanadianAboriginalSyllabics |
|
#x1680 |
#x169F |
Ogham |
| #x16A0 |
#x16FF |
Runic |
|
#x1780 |
#x17FF |
Khmer |
| #x1800 |
#x18AF |
Mongolian |
|
#x1E00 |
#x1EFF |
LatinExtendedAdditional |
| #x1F00 |
#x1FFF |
GreekExtended |
|
#x2000 |
#x206F |
GeneralPunctuation |
| #x2070 |
#x209F |
SuperscriptsandSubscripts |
|
#x20A0 |
#x20CF |
CurrencySymbols |
| #x20D0 |
#x20FF |
CombiningMarksforSymbols |
|
#x2100 |
#x214F |
LetterlikeSymbols |
| #x2150 |
#x218F |
NumberForms |
|
#x2190 |
#x21FF |
Arrows |
| #x2200 |
#x22FF |
MathematicalOperators |
|
#x2300 |
#x23FF |
MiscellaneousTechnical |
| #x2400 |
#x243F |
ControlPictures |
|
#x2440 |
#x245F |
OpticalCharacterRecognition |
| #x2460 |
#x24FF |
EnclosedAlphanumerics |
|
#x2500 |
#x257F |
BoxDrawing |
| #x2580 |
#x259F |
BlockElements |
|
#x25A0 |
#x25FF |
GeometricShapes |
| #x2600 |
#x26FF |
MiscellaneousSymbols |
|
#x2700 |
#x27BF |
Dingbats |
| #x2800 |
#x28FF |
BraillePatterns |
|
#x2E80 |
#x2EFF |
CJKRadicalsSupplement |
| #x2F00 |
#x2FDF |
KangxiRadicals |
|
#x2FF0 |
#x2FFF |
IdeographicDescriptionCharacters |
| #x3000 |
#x303F |
CJKSymbolsandPunctuation |
|
#x3040 |
#x309F |
Hiragana |
| #x30A0 |
#x30FF |
Katakana |
|
#x3100 |
#x312F |
Bopomofo |
| #x3130 |
#x318F |
HangulCompatibilityJamo |
|
#x3190 |
#x319F |
Kanbun |
| #x31A0 |
#x31BF |
BopomofoExtended |
|
#x3200 |
#x32FF |
EnclosedCJKLettersandMonths |
| #x3300 |
#x33FF |
CJKCompatibility |
|
#x3400 |
#x4DB5 |
CJKUnifiedIdeographsExtensionA |
| #x4E00 |
#x9FFF |
CJKUnifiedIdeographs |
|
#xA000 |
#xA48F |
YiSyllables |
| #xA490 |
#xA4CF |
YiRadicals |
|
#xAC00 |
#xD7A3 |
HangulSyllables |
| #xD800 |
#xDB7F |
HighSurrogates |
|
#xDB80 |
#xDBFF |
HighPrivateUseSurrogates |
| #xDC00 |
#xDFFF |
LowSurrogates |
|
#xE000 |
#xF8FF |
PrivateUse |
| #xF900 |
#xFAFF |
CJKCompatibilityIdeographs |
|
#xFB00 |
#xFB4F |
AlphabeticPresentationForms |
| #xFB50 |
#xFDFF |
ArabicPresentationForms-A |
|
#xFE20 |
#xFE2F |
CombiningHalfMarks |
| #xFE30 |
#xFE4F |
CJKCompatibilityForms |
|
#xFE50 |
#xFE6F |
SmallFormVariants |
| #xFE70 |
#xFEFE |
ArabicPresentationForms-B |
|
#xFEFF |
#xFEFF |
Specials |
| #xFF00 |
#xFFEF |
HalfwidthandFullwidthForms |
|
#xFFF0 |
#xFFFD |
Specials |
| #x10300 |
#x1032F |
OldItalic |
|
#x10330 |
#x1034F |
Gothic |
| #x10400 |
#x1044F |
Deseret |
|
#x1D000 |
#x1D0FF |
ByzantineMusicalSymbols |
| #x1D100 |
#x1D1FF |
MusicalSymbols |
|
#x1D400 |
#x1D7FF |
MathematicalAlphanumericSymbols |
| #x20000 |
#x2A6D6 |
CJKUnifiedIdeographsExtensionB |
|
#x2F800 |
#x2FA1F |
CJKCompatibilityIdeographsSupplement |
| #xE0000 |
#xE007F |
Tags |
|
#xF0000 |
#xFFFFD |
PrivateUse |
| #x100000 |
#x10FFFD |
PrivateUse |
|
|
|
|
NOTE: [Unicode
Database] is subject to future revision. For example, the grouping of code
points into blocks might be updated. All ·minimally conforming·
processors ·must· support the blocks
defined in the version of [Unicode
Database] that is current at the time this specification became a W3C
Recommendation. However, implementors are encouraged to support the blocks
defined in any future version of the Unicode Standard.
For example, the ·block escape· for identifying
the ASCII characters is \p{IsBasicLatin}.
[Definition:] A
multi-character escape provides a simple way to identify a commonly used
set of characters:
| Multi-Character Escape |
[37] |
MultiCharEsc |
::= |
'.' | ('\' [sSiIcCdDwW]) |
| |
| Character sequence |
Equivalent ·character class· |
| . |
[^\n\r] |
| \s |
[#x20\t\n\r] |
| \S |
[^\s] |
| \i |
the set of initial name characters, those ·match·ed by Letter |
'_' | ':' |
| \I |
[^\i] |
| \c |
the set of name characters, those ·match·ed by NameChar |
| \C |
[^\c] |
| \d |
\p{Nd} |
| \D |
[^\d] |
| \w |
[#x0000-#x10FFFF]-[\p{P}\p{Z}\p{C}] (all characters
except the set of "punctuation", "separator" and "other" characters)
|
| \W |
[^\w] |
NOTE: The ·regular expression· language
defined here does not attempt to provide a general solution to "regular
expressions" over UCS character sequences. In particular, it does not easily
provide for matching sequences of base characters and combining marks. The
language is targeted at support of "Level 1" features as defined in [Unicode
Regular Expression Guidelines]. It is hoped that future versions of this
specification will provide support for "Level 2" features.
G Glossary (non-normative)
The listing below is for the benefit of readers of a printed version of this
document: it collects together all the definitions which appear in the document
above.
- atomic
- Atomic datatypes are those having values which are regarded by this
specification as being indivisible.
- base
type
- Every datatype that is ·derived· by
restriction is defined in terms of an existing datatype, referred to as
its base type. base types can be either ·primitive· or ·derived·.
- bounded
- A datatype is bounded if its ·value space· has either an ·inclusive upper bound· or an
·exclusive upper bound· and
either an ·inclusive lower bound· and an
·exclusive lower bound·.
- built-in
- Built-in datatypes are those which are defined in this
specification, and can be either ·primitive· or ·derived·;
- canonical
lexical representation
- A canonical lexical representation is a set of literals from among
the valid set of literals for a datatype such that there is a one-to-one
mapping between literals in the canonical lexical representation and
values in the ·value space·.
- cardinality
- Every ·value space· has associated
with it the concept of cardinality. Some ·value space·s are finite,
some are countably infinite while still others could conceivably be
uncountably infinite (although no ·value space· defined by this
specification is uncountable infinite). A datatype is said to have the
cardinality of its ·value space·.
- conformance
to the XML Representation of Schemas
- Processors which accept schemas in the form of XML documents as described
in XML
Representation of Simple Type Definition Schema Components (§4.1.2) (and
other relevant portions of Datatype
components (§4)) are additionally said to provide conformance to the
XML Representation of Schemas, and ·must·, when processing schema
documents, completely and correctly implement all ·Schema Representation Constraint·s in this specification, and ·must· adhere exactly to the
specifications in XML
Representation of Simple Type Definition Schema Components (§4.1.2) (and
other relevant portions of Datatype
components (§4)) for mapping the contents of such documents to schema
components for use in validation.
- constraining
facet
- A constraining facet is an optional property that can be applied to
a datatype to constrain its ·value space·.
- Constraint
on Schemas
- Constraint on Schemas
- datatype
- In this specification, a datatype is a 3-tuple, consisting of a) a
set of distinct values, called its ·value space·, b) a set of
lexical representations, called its ·lexical space·, and c) a set
of ·facet·s that characterize
properties of the ·value space·, individual
values or lexical items.
- derived
- Derived datatypes are those that are defined in terms of other
datatypes.
- error
- error
- exclusive
lower bound
- A value l in an ·ordered· ·value space· L is
said to be an exclusive lower bound of a ·value space· V
(where V is a subset of L) if for all v in V,
l < v.
- exclusive
upper bound
- A value u in an ·ordered· ·value space· U is
said to be an exclusive upper bound of a ·value space· V
(where V is a subset of U) if for all v in V,
u > v.
- facet
- A facet is a single defining aspect of a ·value space·. Generally
speaking, each facet characterizes a ·value space· along
independent axes or dimensions.
- for
compatibility
- for compatibility
- fundamental
facet
- A fundamental facet is an abstract property which serves to
semantically characterize the values in a ·value space·.
- inclusive
lower bound
- A value l in an ·ordered· ·value space· L is
said to be an inclusive lower bound of a ·value space· V
(where V is a subset of L) if for all v in V,
l <= v.
- inclusive
upper bound
- A value u in an ·ordered· ·value space· U is
said to be an inclusive upper bound of a ·value space· V
(where V is a subset of U) if for all v in V,
u >= v.
- itemType
- The ·atomic· datatype that
participates in the definition of a ·list· datatype is known as
the itemType of that ·list· datatype.
- lexical
space
- A lexical space is the set of valid literals for a datatype.
- list
- List datatypes are those having values each of which consists of a
finite-length (possibly empty) sequence of values of an ·atomic· datatype.
- match
- match
- may
- may
- memberTypes
- The datatypes that participate in the definition of a ·union· datatype are known as
the memberTypes of that ·union· datatype.
- minimally
conforming
- Minimally conforming processors ·must· completely and
correctly implement the ·Constraint on Schemas· and ·Validation Rule· .
- must
- must
- non-numeric
- A datatype whose values are not ·numeric· is said to be
non-numeric.
- numeric
- A datatype is said to be numeric if its values are conceptually
quantities (in some mathematical number system).
- ordered
- A ·value space·, and hence a
datatype, is said to be ordered if there exists an ·order-relation· defined for
that ·value space·.
- order-relation
- An order relation on a ·value space· is a
mathematical relation that imposes a ·total order· or a ·partial order· on the members
of the ·value space·.
- partial
order
- A partial order is an ·order-relation· that is
irreflexive, asymmetric and transitive.
- primitive
- Primitive datatypes are those that are not defined in terms of
other datatypes; they exist ab initio.
- regular
expression
- A regular expression is composed from zero or more ·branch·es, separated by
| characters.
- restriction
- A datatype is said to be ·derived· by
restriction from another datatype when values for zero or more ·constraining facet·s are
specified that serve to constrain its ·value space· and/or its ·lexical space· to a subset of
those of its ·base type·.
- Schema
Representation Constraint
- Schema Representation Constraint
- total
order
- A total order is an ·partial order· such that for
no a and b is it the case that a <> b.
- union
- Union datatypes are those whose ·value space·s and ·lexical space·s are the union
of the ·value space·s and ·lexical space·s of one or
more other datatypes.
- user-derived
- User-derived datatypes are those ·derived· datatypes that are
defined by individual schema designers.
- Validation
Rule
- Validation Rule
- value
space
- A value space is the set of values for a given datatype. Each value
in the value space of a datatype is denoted by one or more literals in
its ·lexical space·.
H References
H.2 Non-normative
- Character Model
- Martin J. Dürst and François Yergeau, eds. Character Model for the World
Wide Web. World Wide Web Consortium Working Draft. 2001. Available at: http://www.w3.org/TR/2001/WD-charmod-20010126/
- Gay, DM (1990)
- David M. Gay. Correctly Rounded Binary-Decimal and Decimal-Binary
Conversions. AT&T Bell Laboratories Numerical Analysis Manuscript
90-10, November 1990. Available at: http://cm.bell-labs.com/cm/cs/doc/90/4-10.ps.gz
- HTML 4.01
- World Wide Web Consortium. Hypertext Markup Language, version 4.01.
Available at: http://www.w3.org/TR/1999/REC-html401-19991224/
- IETF INTERNET-DRAFT: IRIs
- L. Masinter and M. Durst. Internationalized Resource Identifiers
2001. Available at: http://www.ietf.org/internet-drafts/draft-masinter-url-i18n-07.txt
- International Earth Rotation Service (IERS)
- International Earth Rotation Service (IERS). See http://maia.usno.navy.mil/
- ISO 11404
- ISO (International Organization for Standardization).
Language-independent Datatypes. See http://www.iso.ch/cate/d19346.html
- ISO 8601
- ISO (International Organization for Standardization). Representations
of dates and times, 1988-06-15. Available at: http://www.iso.ch/markete/8601.pdf
- ISO 8601 Draft Revision
- ISO (International Organization for Standardization). Representations
of dates and times, draft revision, 2000.
- Perl
- The Perl Programming Language. See http://www.perl.com/pub/language/info/software.html
- RDF Schema
- World Wide Web Consortium. RDF Schema Specification. Available at:
http://www.w3.org/TR/2000/CR-rdf-schema-20000327/
- Ruby
- World Wide Web Consortium. Ruby Annotation. Available at: http://www.w3.org/TR/2001/WD-ruby-20010216/
- SQL
- ISO (International Organization for Standardization). ISO/IEC
9075-2:1999, Information technology --- Database languages --- SQL --- Part 2:
Foundation (SQL/Foundation). [Geneva]: International Organization for
Standardization, 1999. See http://www.iso.ch/cate/d26197.html
- U.S. Naval Observatory Time Service Department
- Information about Leap Seconds Available at: http://tycho.usno.navy.mil/leapsec.990505.html
- Unicode Regular Expression Guidelines
- Mark Davis. Unicode Regular Expression Guidelines, 1988. Available
at: http://www.unicode.org/unicode/reports/tr18/
- XML Schema Language: Part 2 Primer
- World Wide Web Consortium. XML Schema Language: Part 2 Primer. Available
at: http://www.w3.org/TR/2001/REC-xmlschema-0-20010502/
- XSL
- World Wide Web Consortium. Extensible Stylesheet Language (XSL).
Available at: http://www.w3.org/TR/2000/CR-xsl-20001121/
I Acknowledgements (non-normative)
The following have contributed material to this draft:
- Asir S. Vedamuthu, webMethods, Inc
- Mark Davis, IBM
Co-editor Ashok Malhotra's work on this specification from March 1999 until
February 2001 was supported by IBM.
The editors acknowledge the members of the XML Schema Working Group, the
members of other W3C Working Groups, and industry experts in other forums who
have contributed directly or indirectly to the process or content of creating
this document. The Working Group is particularly grateful to Lotus Development
Corp. and IBM for providing teleconferencing facilities.
The current members of the XML Schema Working Group are:
Jim Barnette,
Defense Information Systems Agency (DISA); Paul V. Biron, Health Level Seven;
Don Box, DevelopMentor; Allen Brown, Microsoft; Lee Buck, TIBCO Extensibility;
Charles E. Campbell, Informix; Wayne Carr, Intel; Peter Chen, Bootstrap Alliance
and LSU; David Cleary, Progress Software; Dan Connolly, W3C (staff contact); Ugo
Corda, Xerox; Roger L. Costello, MITRE; Haavard Danielson, Progress Software;
Josef Dietl, Mozquito Technologies; David Ezell, Hewlett-Packard Company;
Alexander Falk, Altova GmbH; David Fallside, IBM; Dan Fox, Defense Logistics
Information Service (DLIS); Matthew Fuchs, Commerce One; Andrew Goodchild,
Distributed Systems Technology Centre (DSTC Pty Ltd); Paul Grosso, Arbortext,
Inc; Martin Gudgin, DevelopMentor; Dave Hollander, Contivo, Inc (co-chair); Mary
Holstege, Invited Expert; Jane Hunter, Distributed Systems Technology Centre
(DSTC Pty Ltd); Rick Jelliffe, Academia Sinica; Simon Johnston, Rational
Software; Bob Lojek, Mozquito Technologies; Ashok Malhotra, Microsoft; Lisa
Martin, IBM; Noah Mendelsohn, Lotus Development Corporation; Adrian Michel,
Commerce One; Alex Milowski, Invited Expert; Don Mullen, TIBCO Extensibility;
Dave Peterson, Graphic Communications Association; Jonathan Robie, Software AG;
Eric Sedlar, Oracle Corp.; C. M. Sperberg-McQueen, W3C (co-chair); Bob Streich,
Calico Commerce; William K. Stumbo, Xerox; Henry S. Thompson, University of
Edinburgh; Mark Tucker, Health Level Seven; Asir S. Vedamuthu, webMethods, Inc;
Priscilla Walmsley, XMLSolutions; Norm Walsh, Sun Microsystems; Aki Yoshida, SAP
AG; Kongyi Zhou, Oracle Corp.
The XML Schema Working Group has benefited in its work from the participation
and contributions of a number of people not currently members of the Working
Group, including in particular those named below. Affiliations given are those
current at the time of their work with the WG.
Paula Angerstein, Vignette
Corporation; David Beech, Oracle Corp.; Gabe Beged-Dov, Rogue Wave Software;
Greg Bumgardner, Rogue Wave Software; Dean Burson, Lotus Development
Corporation; Mike Cokus, MITRE; Andrew Eisenberg, Progress Software; Rob Ellman,
Calico Commerce; George Feinberg, Object Design; Charles Frankston, Microsoft;
Ernesto Guerrieri, Inso; Michael Hyman, Microsoft; Renato Iannella, Distributed
Systems Technology Centre (DSTC Pty Ltd); Dianne Kennedy, Graphic Communications
Association; Janet Koenig, Sun Microsystems; Setrag Khoshafian, Technology
Deployment International (TDI); Ara Kullukian, Technology Deployment
International (TDI); Andrew Layman, Microsoft; Dmitry Lenkov, Hewlett-Packard
Company; John McCarthy, Lawrence Berkeley National Laboratory; Murata Makoto,
Xerox; Eve Maler, Sun Microsystems; Murray Maloney, Muzmo Communication, acting
for Commerce One; Chris Olds, Wall Data; Frank Olken, Lawrence Berkeley National
Laboratory; Shriram Revankar, Xerox; Mark Reinhold, Sun Microsystems; John C.
Schneider, MITRE; Lew Shannon, NCR; William Shea, Merrill Lynch; Ralph Swick,
W3C; Tony Stewart, Rivcom; Matt Timmermans, Microstar; Jim Trezzo, Oracle Corp.;
Steph Tryphonas, Microstar